SOLID¶
In case some of us aren’t aware of what SOLID stands for, here it is:
S: Single responsibility principle
O: Open/closed principle
L: Liskov’s substitution principle
I: Interface segregation principle
D: Dependency inversion principle
1. Single responsibility principle¶
The single responsibility principle (SRP) states that a software component (in general, a class) must have only one responsibility. The fact that the class has a sole responsibility means that it is in charge of doing just one concrete thing, and as a consequence of that, we can conclude that it must have only one reason to change.
Only if one thing on the domain problem changes will the class have to be updated. If we have to make modifications to a class, for different reasons, it means the abstraction is incorrect, and that the class has too many responsibilities.T
This design principle helps us build more cohesive abstractions; objects that do one thing, and just one thing, well, following the Unix philosophy. What we want to avoid in all cases is having objects with multiple responsibilities (often called god-objects, because they know too much, or more than they should). These objects group different (mostly unrelated) behaviors, thus making them harder to maintain.
Again, the smaller the class, the better.
The SRP is closely related to the idea of cohesion in software design, which we already explored, when we discussed separation of concerns in software. What we strive to achieve here is that classes are designed in such a way that most of their properties and their attributes are used by its methods, most of the time. When this happens, we know they are related concepts, and therefore it makes sense to group them under the same abstraction.
In a way, this idea is somehow similar to the concept of normalization on relational database design. When we detect that there are partitions on the attributes or methods of the interface of an object, they might as well be moved somewhere else—it is a sign that they are two or more different abstractions mixed into one.
There is another way of looking at this principle. If, when looking at a class, we find methods that are mutually exclusive and do not relate to each other, they are the different responsibilities that have to be broken down into smaller classes.
1.1. A class with too many responsibilities¶
In this example, we are going to create the case for an application that is in charge of reading information about events from a source (this could be log files, a database, or many more sources), and identifying the actions corresponding to each particular log. A design that fails to conform to the SRP would look like this:

Without considering the implementation, the code for the class might look in the following listing:
class SystemMonitor:
def load_activity(self):
"""Get the events from a source, to be processed."""
def identify_events(self):
"""Parse the source raw data into events (domain objects)."""
def stream_events(self):
"""Send the parsed events to an external agent."""
The problem with this class is that it defines an interface with a set of methods that correspond to actions that are orthogonal: each one can be done independently of the rest.
This design flaw makes the class rigid, inflexible, and error-prone because it is hard to maintain. In this example, each method represents a responsibility of the class. Each responsibility entails a reason why the class might need to be modified. In this case, each method represents one of the various reasons why the class will have to be modified.
Consider the loader method, which retrieves the information from a particular source. Regardless of how this is done (we can abstract the implementation details here), it is clear that it will have its own sequence of steps, for instance connecting to the data source, loading the data, parsing it into the expected format, and so on. If any of this changes (for example, we want to change the data structure used for holding the data), the SystemMonitor class will need to change. Ask yourself whether this makes sense. Does a system monitor object have to change because we changed the representation of the data? No.
The same reasoning applies to the other two methods. If we change how we fingerprint events, or how we deliver them to another data source, we will end up making changes to the same class.
It should be clear by now that this class is rather fragile, and not very maintainable. There are lots of different reasons that will impact on changes in this class. Instead, we want external factors to impact our code as little as possible. The solution, again, is to create smaller and more cohesive abstractions.
1.2. Distributing responsibilities¶
To make the solution more maintainable, we separate every method into a different class. This way, each class will have a single responsibility:
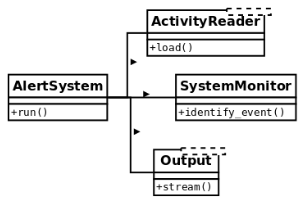
The same behavior is achieved by using an object that will interact with instances of these new classes, using those objects as collaborators, but the idea remains that each class encapsulates a specific set of methods that are independent of the rest. The idea now is that changes on any of these classes do not impact the rest, and all of them have a clear and specific meaning. If we need to change something on how we load events from the data sources, the alert system is not even aware of these changes, so we do not have to modify anything on the system monitor (as long as the contract is still preserved), and the data target is also unmodified.
Changes are now local, the impact is minimal, and each class is easier to maintain.
The new classes define interfaces that are not only more maintainable but also reusable.
Imagine that now, in another part of the application, we also need to read the activity from
the logs, but for different purposes. With this design, we can simply use objects of type
ActivityReader (which would actually be an interface, but for the purposes of this
section, that detail is not relevant and will be explained later for the next principles). This
would make sense, whereas it would not have made sense in the previous design, because
attempts to reuse the only class we had defined would have also carried extra methods
(such as identify_events(), or stream_events()) that were not needed at all.
One important clarification is that the principle does not mean at all that each class must have a single method. Any of the new classes might have extra methods, as long as they correspond to the same logic that that class is in charge of handling.
2. The open/closed principle¶
The open/closed principle (OCP) states that a module should be both open and closed (but with respect to different aspects).
When designing a class, for instance, we should carefully encapsulate the logic so that it has good maintenance, meaning that we will want it to be open to extension but closed for modification.
What this means in simple terms is that, of course, we want our code to be extensible, to adapt to new requirements, or changes in the domain problem. This means that, when something new appears on the domain problem, we only want to add new things to our model, not change anything existing that is closed to modification.
If, for some reason, when something new has to be added, we found ourselves modifying the code, then that logic is probably poorly designed. Ideally, when requirements change, we want to just have to extend the module with the new required behavior in order to comply with the new requirements, but without having to modify the code.
This principle applies to several software abstractions. It could be a class or even a module. In the following two subsections, we will see examples of each one, respectively.
2.1. Example of maintainability perils for not following the open/closed principle¶
Let’s begin with an example of a system that is designed in such a way that does not follow the open/closed principle, in order to see the maintainability problems this carries, and the inflexibility of such a design.
The idea is that we have a part of the system that is in charge of identifying events as they occur in another system, which is being monitored. At each point, we want this component to identify the type of event, correctly, according to the values of the data that was previously gathered (for simplicity, we will assume it is packaged into a dictionary, and was previously retrieved through another means such as logs, queries, and many more). We have a class that, based on this data, will retrieve the event, which is another type with its own hierarchy.
A first attempt to solve this problem might look like this:
class Event:
def __init__(self, raw_data):
self.raw_data = raw_data
class UnknownEvent(Event):
"""A type of event that cannot be identified from its data."""
class LoginEvent(Event):
"""A event representing a user that has just entered the system."""
class LogoutEvent(Event):
"""An event representing a user that has just left the system."""
class SystemMonitor:
"""Identify events that occurred in the system."""
def __init__(self, event_data):
self.event_data = event_data
def identify_event(self):
if (self.event_data["before"]["session"] == 0 and
self.event_data["after"]["session"] == 1):
return LoginEvent(self.event_data)
elif (self.event_data["before"]["session"] == 1 and
self.event_data["after"]["session"] == 0):
return LogoutEvent(self.event_data)
return UnknownEvent(self.event_data)
The following is the expected behavior of the preceding code:
>>> l1 = SystemMonitor({"before": {"session": 0}, "after": {"session": 1}})
>>> l1.identify_event().__class__.__name__
'LoginEvent'
>>> l2 = SystemMonitor({"before": {"session": 1}, "after": {"session": 0}})
>>> l2.identify_event().__class__.__name__
'LogoutEvent'
>>> l3 = SystemMonitor({"before": {"session": 1}, "after": {"session": 1}})
>>> l3.identify_event().__class__.__name__
'UnknownEvent'
We can clearly notice the hierarchy of event types, and some business logic to construct
them. For instance, when there was no previous flag for a session, but there is now, we
identify that record as a login event. Conversely, when the opposite happens, it means that
it was a logout event. If it was not possible to identify an event, an event of type unknown
is returned. This is to preserve polymorphism by following the null object pattern (instead
of returning None, it retrieves an object of the corresponding type with some default logic).
This design has some problems. The first issue is that the logic for determining the types of events is centralized inside a monolithic method. As the number of events we want to support grows, this method will as well, and it could end up being a very long method, which is bad because, as we have already discussed, it will not be doing just one thing and one thing well.
On the same line, we can see that this method is not closed for modification. Every time we
want to add a new type of event to the system, we will have to change something in this
method (not to mention, that the chain of elif statements will be a nightmare to read!).
We want to be able to add new types of event without having to change this method (closed for modification). We also want to be able to support new types of event (open for extension) so that when a new event is added, we only have to add code, not change the code that already exists.
2.2. Refactoring the events system for extensibility¶
The problem with the previous example was that the SystemMonitor class was interacting directly with the concrete classes it was going to retrieve.
In order to achieve a design that honors the open/closed principle, we have to design toward abstractions.
A possible alternative would be to think of this class as it collaborates with the events, and then we delegate the logic for each particular type of event to its corresponding class:
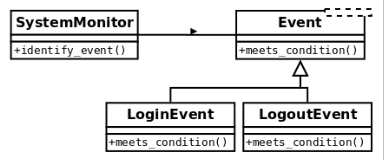
Then we have to add a new (polymorphic) method to each type of event with the single responsibility of determining if it corresponds to the data being passed or not, and we also have to change the logic to go through all events, finding the right one.
The new code should look like this:
class Event:
def __init__(self, raw_data):
self.raw_data = raw_data
@staticmethod
def meets_condition(event_data: dict):
return False
class UnknownEvent(Event):
"""A type of event that cannot be identified from its data"""
class LoginEvent(Event):
@staticmethod
def meets_condition(event_data: dict):
return (event_data["before"]["session"] == 0 and event_data["after"]["session"] == 1)
class LogoutEvent(Event):
@staticmethod
def meets_condition(event_data: dict):
return (event_data["before"]["session"] == 1 and event_data["after"]["session"] == 0)
class SystemMonitor:
"""Identify events that occurred in the system."""
def __init__(self, event_data):
self.event_data = event_data
def identify_event(self):
for event_cls in Event.__subclasses__():
try:
if event_cls.meets_condition(self.event_data):
return event_cls(self.event_data)
except KeyError:
continue
return UnknownEvent(self.event_data)
Notice how the interaction is now oriented toward an abstraction (in this case, it would be
the generic base class Event, which might even be an abstract base class or an interface, but
for the purposes of this example it is enough to have a concrete base class). The method no
longer works with specific types of event, but just with generic events that follow a
common interface—they are all polymorphic with respect to the meets_condition method.
Notice how events are discovered through the __subclasses__() method. Supporting
new types of event is now just about creating a new class for that event that has to inherit
from Event and implement its own meets_condition() method, according to its specific
business logic.
2.3. Extending the events system¶
Now, let’s prove that this design is actually as extensible as we wanted it to be. Imagine that a new requirement arises, and we have to also support events that correspond to transactions that the user executed on the monitored system.
The class diagram for the design has to include such a new event type, as in the following:
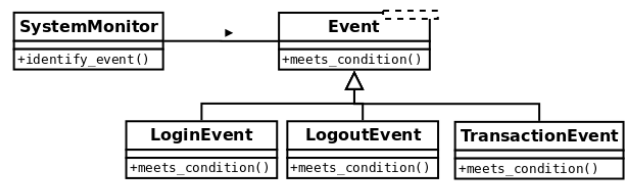
Only by adding the code to this new class does the logic keep working as expected:
class Event:
def __init__(self, raw_data):
self.raw_data = raw_data
@staticmethod
def meets_condition(event_data: dict):
return False
class UnknownEvent(Event):
"""A type of event that cannot be identified from its data"""
class LoginEvent(Event):
@staticmethod
def meets_condition(event_data: dict):
return (event_data["before"]["session"] == 0 and event_data["after"]["session"] == 1)
class LogoutEvent(Event):
@staticmethod
def meets_condition(event_data: dict):
return (event_data["before"]["session"] == 1 and event_data["after"]["session"] == 0)
class TransactionEvent(Event):
"""Represents a transaction that has just occurred on the system."""
@staticmethod
def meets_condition(event_data: dict):
return event_data["after"].get("transaction") is not None
class SystemMonitor:
"""Identify events that occurred in the system."""
def __init__(self, event_data):
self.event_data = event_data
def identify_event(self):
for event_cls in Event.__subclasses__():
try:
if event_cls.meets_condition(self.event_data):
return event_cls(self.event_data)
except KeyError:
continue
return UnknownEvent(self.event_data)
We can verify that the previous cases work as before and that the new event is also correctly identified:
>>> l1 = SystemMonitor({"before": {"session": 0}, "after": {"session": 1}})
>>> l1.identify_event().__class__.__name__
'LoginEvent'
>>> l2 = SystemMonitor({"before": {"session": 1}, "after": {"session": 0}})
>>> l2.identify_event().__class__.__name__
'LogoutEvent'
>>> l3 = SystemMonitor({"before": {"session": 1}, "after": {"session": 1}})
>>> l3.identify_event().__class__.__name__
'UnknownEvent'
>>> l4 = SystemMonitor({"after": {"transaction": "Tx001"}})
>>> l4.identify_event().__class__.__name__
'TransactionEvent'
Notice that the SystemMonitor.identify_event() method did not change at all when
we added the new event type. We, therefore, say that this method is closed with respect to
new types of event.
Conversely, the Event class allowed us to add a new type of event when we were required
to do so. We then say that events are open for an extension with respect to new types.
This is the true essence of this principle—when something new appears on the domain problem, we only want to add new code, not modify existing code.
2.4. Final thoughts about the OCP¶
As you might have noticed, this principle is closely related to effective use of polymorphism. We want to design toward abstractions that respect a polymorphic contract that the client can use, to a structure that is generic enough that extending the model is possible, as long as the polymorphic relationship is preserved.
This principle tackles an important problem in software engineering: maintainability. The perils of not following the OCP are ripple effects and problems in the software where a single change triggers changes all over the code base, or risks breaking other parts of the code.
One important final note is that, in order to achieve this design in which we do not change the code to extend behavior, we need to be able to create proper closure against the abstractions we want to protect (in this example, new types of event). This is not always possible in all programs, as some abstractions might collide (for example, we might have a proper abstraction that provides closure against a requirement, but does not work for other types of requirements). In these cases, we need to be selective and apply a strategy that provides the best closure for the types of requirement that require to be the most extensible.
3. Liskov’s substitution principle¶
Liskov’s substitution principle (LSP) states that there is a series of properties that an object type must hold to preserve reliability on its design.
The main idea behind LSP is that, for any class, a client should be able to use any of its subtypes indistinguishably, without even noticing, and therefore without compromising the expected behavior at runtime. This means that clients are completely isolated and unaware of changes in the class hierarchy.
More formally, this is the original definition (LISKOV 01) of Liskov’s substitution principle:
if S is a subtype of T, then objects of type T may be replaced by objects of type S, without breaking the program.
This can be understood with the help of a generic diagram such as the following one.
Imagine that there is some client class that requires (includes) objects of another type. Generally speaking, we will want this client to interact with objects of some type, namely, it will work through an interface.
Now, this type might as well be just a generic interface definition, an abstract class or an interface, not a class with the behavior itself. There may be several subclasses extending this type (described in the diagram with the name Subtype, up to N). The idea behind this principle is that, if the hierarchy is correctly implemented, the client class has to be able to work with instances of any of the subclasses without even noticing. These objects should be interchangeable, as shown here:
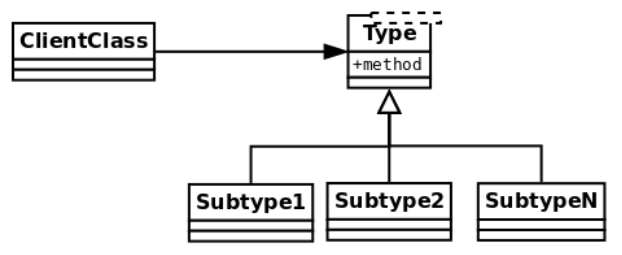
This is related to other design principles we have already visited, like designing to interfaces. A good class must define a clear and concise interface, and as long as subclasses honor that interface, the program will remain correct.
As a consequence of this, the principle also relates to the ideas behind designing by contract. There is a contract between a given type and a client. By following the rules of LSP, the design will make sure that subclasses respect the contracts as they are defined by parent classes.
There are some scenarios so notoriously wrong with respect to the LSP that they can be easily identified.
3.1. Detecting incorrect datatypes in method signatures¶
By using type annotations throughout our code, we can quickly detect some basic errors early and check basic compliance with LSP.
One common code smell is that one of the subclasses of the parent class were to override a method in an incompatible fashion:
class Event:
...
def meets_condition(self, event_data: dict) -> bool:
return False
class LoginEvent(Event):
def meets_condition(self, event_data: list) -> bool:
return bool(event_data)
The violation to LSP is clear—since the derived class is using a type for the event_data
parameter which is different from the one defined on the base class, we cannot expect them
to work equally. Remember that, according to this principle, any caller of this hierarchy has
to be able to work with Event or LoginEvent transparently, without noticing any
difference. Interchanging objects of these two types should not make the application fail.
Failure to do so would break the polymorphism on the hierarchy.
The same error would have occurred if the return type was changed for something other than a Boolean value. The rationale is that clients of this code are expecting a Boolean value to work with. If one of the derived classes changes this return type, it would be breaking the contract, and again, we cannot expect the program to continue working normally.
A quick note about types that are not the same but share a common interface: even though
this is just a simple example to demonstrate the error, it is still true that both dictionaries
and lists have something in common; they are both iterables. This means that in some cases,
it might be valid to have a method that expects a dictionary and another one expecting to
receive a list, as long as both treat the parameters through the iterable interface. In this case,
the problem would not lie in the logic itself (LSP might still apply), but in the definition of
the types of the signature, which should read neither list nor dict, but a union of both.
Regardless of the case, something has to be modified, whether it is the code of the method,
the entire design, or just the type annotations.
Another strong violation of LSP is when, instead of varying the types of the parameters on the hierarchy, the signatures of the methods differ completely. This might seem like quite a blunder, but detecting it would not always be so easy to remember; Python is interpreted, so there is no compiler to detect these type of error early on, and therefore they will not be caught until runtime.
In the presence of a class that breaks the compatibility defined by the hierarchy (for example, by changing the signature of the method, adding an extra parameter, and so on) shown as follows:
class LogoutEvent(Event):
def meets_condition(self, event_data: dict, override: bool) -> bool:
if override:
return True
3.2. More subtle cases of LSP violations¶
Cases where contracts are modified are particularly harder to detect. Given that the entire idea of LSP is that subclasses can be used by clients just like their parent class, it must also be true that contracts are correctly preserved on the hierarchy.
Remember that, when designing by contract, the contract between the client and supplier sets some rules: the client must provide the preconditions to the method, which the supplier might validate, and it returns some result to the client that it will check in the form of postconditions.
The parent class defines a contract with its clients. Subclasses of this one must respect such a contract. This means that, for example:
A subclass can never make preconditions stricter than they are defined on the parent class
A subclass can never make postconditions weaker than they are defined on the parent class
Consider the example of the events hierarchy defined in the previous section, but now with a change to illustrate the relationship between LSP and DbC.
This time, we are going to assume a precondition for the method that checks the criteria
based on the data, that the provided parameter must be a dictionary that contains both keys
“before” and “after”, and that their values are also nested dictionaries. This allows us to
encapsulate even further, because now the client does not need to catch the KeyError
exception, but instead just calls the precondition method (assuming that is acceptable to fail
if the system is operating under the wrong assumptions). As a side note, it is good that we
can remove this from the client, as now, SystemMonitor does not require to know which
types of exceptions the methods of the collaborator class might raise (remember that
exception weaken encapsulation, as they require the caller to know something extra about
the object they are calling).
Such a design might be represented with the following changes in the code:
class Event:
def __init__(self, raw_data):
self.raw_data = raw_data
@staticmethod
def meets_condition(event_data: dict):
return False
@staticmethod
def meets_condition_pre(event_data: dict):
"""Precondition of the contract of this interface.
Validate that the ``event_data`` parameter is properly formed.
"""
assert isinstance(event_data, dict), f"{event_data!r} is not a dict"
for moment in ("before", "after"):
assert moment in event_data, f"{moment} not in {event_data}"
assert isinstance(event_data[moment], dict)
And now the code that tries to detect the correct event type just checks the precondition once, and proceeds to find the right type of event:
class SystemMonitor:
"""Identify events that occurred in the system."""
def __init__(self, event_data):
self.event_data = event_data
def identify_event(self):
Event.meets_condition_pre(self.event_data)
event_cls = next((event_cls for event_cls in Event.__subclasses__()
if event_cls.meets_condition(self.event_data)), UnknownEvent)
return event_cls(self.event_data)
The contract only states that the top-level keys “before” and “after” are mandatory and that their values should also be dictionaries. Any attempt in the subclasses to demand a more restrictive parameter will fail.
The class for the transaction event was originally correctly designed. Look at how the code does not impose a restriction on the internal key named “transaction”; it only uses its value if it is there, but this is not mandatory:
class TransactionEvent(Event):
"""Represents a transaction that has just occurred on the system."""
@staticmethod
def meets_condition(event_data: dict):
return event_data["after"].get("transaction") is not None
However, the original two methods are not correct, because they demand the presence of a
key named “session”, which is not part of the original contract. This breaks the contract,
and now the client cannot use these classes in the same way it uses the rest of them because
it will raise KeyError.
After fixing this (changing the square brackets for the .get() method), the order on the LSP has been reestablished, and polymorphism prevails:
>>> l1 = SystemMonitor({"before": {"session": 0}, "after": {"session": 1}})
>>> l1.identify_event().__class__.__name__
'LoginEvent'
>>> l2 = SystemMonitor({"before": {"session": 1}, "after": {"session": 0}})
>>> l2.identify_event().__class__.__name__
'LogoutEvent'
>>> l3 = SystemMonitor({"before": {"session": 1}, "after": {"session": 1}})
>>> l3.identify_event().__class__.__name__
'UnknownEvent'
>>> l4 = SystemMonitor({"before": {}, "after": {"transaction": "Tx001"}})
>>> l4.identify_event().__class__.__name__
'TransactionEvent'
We have to be careful when designing classes that we do not accidentally change the input or output of the methods in a way that would be incompatible with what the clients are originally expecting.
3.3. Remarks on the LSP¶
The LSP is fundamental to a good object-oriented software design because it emphasizes one of its core traits—polymorphism. It is about creating correct hierarchies so that classes derived from a base one are polymorphic along the parent one, with respect to the methods on their interface.
It is also interesting to notice how this principle relates to the previous one—if we attempt to extend a class with a new one that is incompatible, it will fail, the contract with the client will be broken, and as a result such an extension will not be possible (or, to make it possible, we would have to break the other end of the principle and modify code in the client that should be closed for modification, which is completely undesirable and unacceptable).
Carefully thinking about new classes in the way that LSP suggests helps us to extend the hierarchy correctly. We could then say that LSP contributes to the OCP.
4. Interface segregation¶
The interface segregation principle (ISP) provides some guidelines over an idea that we have revisited quite repeatedly already: that interfaces should be small.
In object-oriented terms, an interface is represented by the set of methods an object exposes. This is to say that all the messages that an object is able to receive or interpret constitute its interface, and this is what other clients can request. The interface separates the definition of the exposed behavior for a class from its implementation.
In Python, interfaces are implicitly defined by a class according to its methods. This is because Python follows the so-called duck typing principle.
Traditionally, the idea behind duck typing was that any object is really represented by the methods it has, and by what it is capable of doing. This means that, regardless of the type of the class, its name, its docstring, class attributes, or instance attributes, what ultimately defines the essence of the object are the methods it has. The methods defined on a class (what it knows how to do) are what determines what that object will actually be. It was called duck typing because of the idea that “If it walks like a duck, and quacks like a duck, it must be a duck.”
For a long time, duck typing was the sole way interfaces were defined in Python. Later on,
Python 3 (PEP-3119) introduced the concept of abstract base classes as a way to define
interfaces in a different way. The basic idea of abstract base classes is that they define a
basic behavior or interface that some derived classes are responsible for implementing. This
is useful in situations where we want to make sure that certain critical methods are actually
overridden, and it also works as a mechanism for overriding or extending the functionality
of methods such as isinstance().
This module also contains a way of registering some types as part of a hierarchy, in what is called a virtual subclass. The idea is that this extends the concept of duck typing a little bit further by adding a new criterion—walks like a duck, quacks like a duck, or… it says it is a duck.
These notions of how Python interprets interfaces are important for understanding this principle and the next one.
In abstract terms, this means that the ISP states that, when we define an interface that provides multiple methods, it is better to instead break it down into multiple ones, each one containing fewer methods (preferably just one), with a very specific and accurate scope. By separating interfaces into the smallest possible units, to favor code reusability, each class that wants to implement one of these interfaces will most likely be highly cohesive given that it has a quite definite behavior and set of responsibilities.
4.1. An interface that provides too much¶
Now, we want to be able to parse an event from several data sources, in different formats (XML and JSON, for instance). Following good practice, we decide to target an interface as our dependency instead of a concrete class, and something like the following is devised:

In order to create this as an interface in Python, we would use an abstract base class and
define the methods (from_xml() and from_json()) as abstract, to force derived classes to
implement them. Events that derive from this abstract base class and implement these
methods would be able to work with their corresponding types.
But what if a particular class does not need the XML method, and can only be constructed from a JSON? It would still carry the from_xml() method from the interface, and since it does not need it, it will have to pass. This is not very flexible as it creates coupling and forces clients of the interface to work with methods that they do not need.
4.2. The smaller the interface, the better¶
It would be better to separate this into two different interfaces, one for each method:
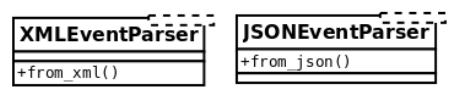
With this design, objects that derive from XMLEventParser and implement the
from_xml() method will know how to be constructed from an XML, and the same for a
JSON file, but most importantly, we maintain the orthogonality of two independent
functions, and preserve the flexibility of the system without losing any functionality that
can still be achieved by composing new smaller objects.
There is some resemblance to the SRP, but the main difference is that here we are talking about interfaces, so it is an abstract definition of behavior. There is no reason to change because there is nothing there until the interface is actually implemented. However, failure to comply with this principle will create an interface that will be coupled with orthogonal functionality, and this derived class will also fail to comply with the SRP (it will have more than one reason to change).
4.3. How small should an interface be?¶
The point made in the previous section is valid, but it also needs a warning: avoid a dangerous path if it’s misunderstood or taken to the extreme.
A base class (abstract or not) defines an interface for all the other classes to extend it. The fact that this should be as small as possible has to be understood in terms of cohesion: it should do one thing. That doesn’t mean it must necessarily have one method. In the previous example, it was by coincidence that both methods were doing totally disjoint things, hence it made sense to separate them into different classes.
But it could be the case that more than one method rightfully belongs to the same class.
Imagine that you want to provide a mixin class that abstracts certain logic in a context
manager so that all classes derived from that mixin gain that context manager logic for free.
As we already know, a context manager entails two methods: __enter__ and __exit__.
They must go together, or the outcome will not be a valid context manager at all!
Failure to place both methods in the same class will result in a broken component that is not only useless, but also misleadingly dangerous. Hopefully, this exaggerated example works as a counter-balance to the one in the previous section, and together the reader can get a more accurate picture about designing interfaces.
5. Dependency inversion¶
The dependency inversion principle (DIP) proposes an interesting design principle by which we protect our code by making it independent of things that are fragile, volatile, or out of our control. The idea of inverting dependencies is that our code should not adapt to details or concrete implementations, but rather the other way around: we want to force whatever implementation or detail to adapt to our code via a sort of API.
Abstractions have to be organized in such a way that they do not depend on details, but rather the other way around: the details (concrete implementations) should depend on abstractions.
Imagine that two objects in our design need to collaborate, A and B. A works with an instance of B, but as it turns out, our module doesn’t control B directly (it might be an external library, or a module maintained by another team, and so on). If our code heavily depends on B, when this changes the code will break. To prevent this, we have to invert the dependency: make B have to adapt to A. This is done by presenting an interface and forcing our code not to depend on the concrete implementation of B, but rather on the interface we have defined. It is then B’s responsibility to comply with that interface.
In line with the concepts explored in previous sections, abstractions also come in the form of interfaces (or abstract base classes in Python).
In general, we could expect concrete implementations to change much more frequently than abstract components. It is for this reason that we place abstractions (interfaces) as flexibility points where we expect our system to change, be modified, or extended without the abstraction itself having to be changed.
5.1. A case of rigid dependencies¶
The last part of our event’s monitoring system is to deliver the identified events to a data
collector to be further analyzed. A naive implementation of such an idea would consist of
having an event streamer class that interacts with a data destination, for example, Syslog:
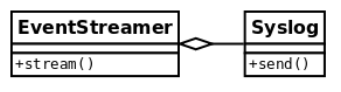
However, this design is not very good, because we have a high-level class
(EventStreamer) depending on a low-level one (Syslog is an implementation detail). If
something changes in the way we want to send data to Syslog, EventStreamer will have
to be modified. If we want to change the data destination for a different one or add new
ones at runtime, we are also in trouble because we will find ourselves constantly modifying
the stream() method to adapt it to these requirements.
5.2. Inverting the dependencies¶
The solution to these problems is to make EventStreamer work with an interface, rather
than a concrete class. This way, implementing this interface is up to the low-level classes
that contain the implementation details:
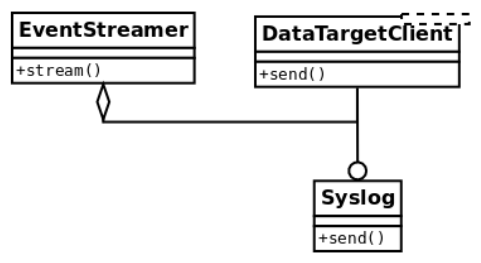
Now there is an interface that represents a generic data target where data is going to be sent
to. Notice how the dependencies have now been inverted since EventStreamer does not
depend on a concrete implementation of a particular data target, it does not have to change
in line with changes on this one, and it is up to every particular data target; to implement
the interface correctly and adapt to changes if necessary.
In other words, the original EventStreamer of the first implementation only worked with
objects of type Syslog, which was not very flexible. Then we realized that it could work
with any object that could respond to a .send() message, and identified this method as the
interface that it needed to comply with. Now, in this version, Syslog is actually extending
the abstract base class named DataTargetClient, which defines the send() method.
From now on, it is up to every new type of data target (email, for instance) to extend this
abstract base class and implement the send() method.
We can even modify this property at runtime for any other object that implements a
send() method, and it will still work. This is the reason why it is often called dependency
injection: because the dependency can be provided dynamically.
The avid reader might be wondering why this is actually necessary. Python is flexible
enough (sometimes too flexible), and will allow us to provide an object like
EventStreamer with any particular data target object, without this one having to comply
with any interface because it is dynamically typed. The question is this: why do we need to
define the abstract base class (interface) at all when we can simply pass an object with a
send() method to it?
In all fairness, this is true; there is actually no need to do that, and the program will work
just the same. After all, polymorphism does not mean (or require) inheritance to work.
However, defining the abstract base class is a good practice that comes with some
advantages, the first one being duck typing. Together with as duck typing, we can mention
the fact that the models become more readable: remember that inheritance follows the rule
of is a, so by declaring the abstract base class and extending from it, we are saying that, for
instance, Syslog is DataTargetClient, which is something users of your code can read
and understand (again, this is duck typing).
All in all, it is not mandatory to define the abstract base class, but it is desirable in order to achieve a cleaner design.