Descriptors¶
Descriptors are another distinctive feature of Python that takes object-oriented programming to another level, and their potential allows users to build more powerful and reusable abstractions. Most of the time, the full potential of descriptors is observed in libraries or frameworks.
A descriptor lets you customize what should be done when you refer to an attribute of an object.
Descriptors are the base of a complex attribute access in Python. They are used internally to
implement properties, methods, class methods, static methods, and the super type. They
are classes that define how attributes of another class can be accessed. In other words, a
class can delegate the management of an attribute to another one.
Important
Like every advanced Python syntax feature, this one should also be used with caution and documented well in code. For inexperienced developers, the altered class behavior might be very confusing and unexpected, because descriptors affect the very basic part of class behavior. Because of that, it is very important to make sure that all your team members are familiar with descriptors and understand this concept well if it plays an important role in your project’s code base.
1. A first look at descriptors¶
First, we will explore the main idea behind descriptors to understand their mechanics and internal workings. Once this is clear, it will be easier to assimilate how the different types of descriptors work, which we will explore in the next section.
Once we have a first understanding of the idea behind descriptors, we will look at an example where their use gives us a cleaner and more Pythonic implementation.
1.1. The machinery behind descriptors¶
The way descriptors work is not all that complicated, but the problem with them is that there are a lot of caveats to take into consideration, so the implementation details are of the utmost importance here.
In order to implement descriptors, we need at least two classes. For the purposes of this generic example, we are going to call the client class to the one that is going to take advantage of the functionality we want to implement in the descriptor (this class is generally just a domain model one, a regular abstraction we create for our solution), and we are going to call the descriptor class to the one that implements the logic of the descriptor.
A descriptor is, therefore, just an object that is an instance of a class that implements the descriptor protocol. This means that this class must have its interface containing at least one of the following magic methods (part of the descriptor protocol as of Python 3.6+):
__get__(self, obj, owner=None): This is called whenever the attribute is read (referred to as agetter)__set__(self, obj, value): .This is called whenever the attribute is set. In the following examples, I will refer to this as asetter.__delete__(self, obj): This is called whendelis invoked on the attribute.__set_name__(self, owner, name)
A descriptor that implements __get__() and __set__() is called a data descriptor. If it
just implements __get__(), then it is called a non-data descriptor.
Methods of this protocol are, in fact, called by the object’s
special __getattribute__() method (do not confuse it with __getattr__(), which has
a different purpose) on every attribute lookup. Whenever such a lookup is performed,
either by using a dotted notation in the form of instance.attribute, or by using
the getattr(instance, 'attribute') function call, the __getattribute__() method
is implicitly invoked and it looks for an attribute in the following order:
It verifies whether the attribute is a data descriptor on the class object of the instance.
If not, it looks to see whether the attribute can be found in the
__dict__lookup of the instance object.Finally, it looks to see whether the attribute is a non-data descriptor on the class object of the instance.
In other words, data descriptors take precedence over __dict__ lookup,
and __dict__ lookup takes precedence over non-data descriptors. Without __dict__
taking precedence over non-data descriptors, we would not be able
to dynamically override specific methods on already constructed instances at runtime.
Fortunately, thanks to how descriptors work in Python, it is possible; so, developers may
use a popular technique called monkey patching to change the way in which instances
work without the need for subclassing.
For the purposes of this initial high-level introduction, the following naming convention will be used:
ClientClass: The domain-level abstraction that will take advantage of the functionality to be implemented by the descriptor. This class is said to be a client of the descriptor. This class contains a class attribute (named descriptor by this convention), which is an instance of DescriptorClass.
DescriptorClass: The class that implements the descriptor itself. This class should implement some of the aforementioned magic methods that entail the descriptor protocol.
client: An instance of ClientClass.
client = ClientClass()descriptor: An instance of DescriptorClass.
descriptor = DescriptorClass(). This object is a class attribute that is placed in ClientClass.
This relationship is illustrated in the following diagram:
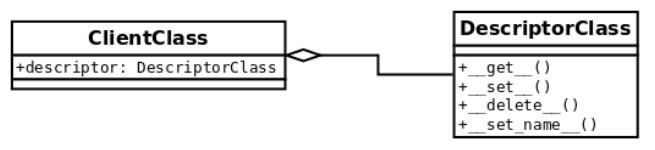
A very important observation to keep in mind is that for this protocol to work, the
descriptor object has to be defined as a class attribute. Creating this object as an instance
attribute will not work, so it must be in the body of the class, and not in the init method.
Note
Always place the descriptor object as a class attribute!
On a slightly critical note, readers can also note that it is possible to implement the descriptor protocol partially: not all methods must always be defined; instead, we can implement only those we need, as we will see shortly.
So, now we have the structure in place: we know what elements are set and how they
interact. We need a class for the descriptor, another class that will consume the logic of
the descriptor, which, in turn, will have a descriptor object (an instance of the
DescriptorClass) as a class attribute, and instances of ClientClass that will follow the
descriptor protocol when we call for the attribute named descriptor. But now what?
How does all of this fit into place at runtime?
Normally, when we have a regular class and we access its attributes, we simply obtain the objects as we expect them, and even their properties, as in the following example:
>>> class Attribute:
... value = 42
...
>>> class Client:
... attribute = Attribute()
...
>>> Client().attribute
<__main__.Attribute object at 0x7ff37ea90940>
>>> Client().attribute.value
42
But, in the case of descriptors, something different happens. When an object is defined as a
class attribute (and this one is a descriptor), when a client requests this attribute,
instead of getting the object itself (as we would expect from the previous example), we get
the result of having called the __get__ magic method.
Let’s start with some simple code that only logs information about the context, and returns the same client object:
class DescriptorClass:
def __get__(self, instance, owner):
if instance is None:
return self
logger.info("Call: %s.__get__(%r, %r)",
self.__class__.__name__,instance, owner)
return instance
class ClientClass:
descriptor = DescriptorClass()
When running this code, and requesting the descriptor attribute of an instance of ClientClass, we will discover that we are, in fact, not getting an instance of DescriptorClass, but whatever its __get__() method returns instead:
>>> client = ClientClass()
>>> client.descriptor
INFO:Call: DescriptorClass.__get__(<ClientClass object at 0x...>, <class 'ClientClass'>)
<ClientClass object at 0x...>
>>> client.descriptor is client
INFO:Call: DescriptorClass.__get__(ClientClass object at 0x...>, <class 'ClientClass'>)
True
Notice how the logging line, placed under the __get__ method, was called instead of just
returning the object we created. In this case, we made that method return the client itself,
hence making true a comparison of the last statement. The parameters of this method are
explained in more detail in the following subsections when we explore each method in
more detail.
Starting from this simple, yet demonstrative example, we can start creating more complex
abstractions and better decorators, because the important note here is that we have a new
(powerful) tool to work with. Notice how this changes the control flow of the program in a
completely different way. With this tool, we can abstract all sorts of logic behind the
__get__ method, and make the descriptor transparently run all sorts of transformations
without clients even noticing. This takes encapsulation to a new level.
1.2. Exploring each method of the descriptor protocol¶
Up until now, we have seen quite a few examples of descriptors in action, and we got the idea of how they work. These examples gave us a first glimpse of the power of descriptors, but you might be wondering about some implementation details and idioms whose explanation we failed to address.
Since descriptors are just objects, these methods take self as the first parameter. For all of
them, this just means the descriptor object itself.
In this section, we will explore each method of the descriptor protocol, in full detail, explaining what each parameter signifies, and how they are intended to be used.
1.2.1. __get__(self, instance, owner)¶
The first parameter, instance, refers to the object from which the descriptor is being
called. In our first example, this would mean the client object.
The owner parameter is a reference to the class of that object, which following our example
would be ClientClass.
From the previous paragraph we conclude that the parameter named instance in the
signature of __get__ is the object over which the descriptor is taking action, and owner is
the class of instance. The avid reader might be wondering why is the signature define like
this, after all the class can be taken from instance directly (owner = instance.__class__). There is an edge case:
when the descriptor is called from the class (ClientClass), not from the instance (client), then the value of instance is None,
but we might still want to do some processing in that case.
With the following simple code we can demonstrate the difference of when a descriptor is
being called from the class, or from an instance. In this case, the __get__ method is doing
two separate things for each case.
class DescriptorClass:
def __get__(self, instance, owner):
if instance is None:
return f"{self.__class__.__name__}.{owner.__name__}"
return f"value for {instance}"
class ClientClass:
descriptor = DescriptorClass()
When we call it from ClientClass directly it will do one thing, which is composing a namespace with the names of the classes:
>>> ClientClass.descriptor
'DescriptorClass.ClientClass'
And then if we call it from an object we have created, it will return the other message instead:
>>> ClientClass().descriptor
'value for <descriptors_methods_1.ClientClass object at 0x...>'
In general, unless we really need to do something with the owner parameter, the most
common idiom, is to just return the descriptor itself, when instance is None.
1.2.2. __set__(self, instance, value)¶
This method is called when we try to assign something to a descriptor. It is activated
with statements such as the following, in which a descriptor is an object that implements
__set__(). The instance parameter, in this case, would be client, and
the value would be the “value” string: client.descriptor = "value"
If client.descriptor doesn’t implement __set__(), then “value” will override the
descriptor entirely.
Note
Be careful when assigning a value to an attribute that is a descriptor. Make sure it implements the __set__ method, and that we are not causing an undesired side effect.
By default, the most common use of this method is just to store data in an object. Nevertheless, we have seen how powerful descriptors are so far, and that we can take advantage of them, for example, if we were to create generic validation objects that can be applied multiple times (again, this is something that if we don’t abstract, we might end up repeating multiple times in setter methods of properties).
The following listing illustrates how we can take advantage of this method in order to create generic validation objects for attributes, which can be created dynamically with functions to validate on the values before assigning them to the object:
class Validation:
def __init__(self, validation_function, error_msg: str):
self.validation_function = validation_function
self.error_msg = error_msg
def __call__(self, value):
if not self.validation_function(value):
raise ValueError(f"{value!r} {self.error_msg}")
class Field:
def __init__(self, *validations):
self._name = None
self.validations = validations
def __set_name__(self, owner, name):
self._name = name
def __get__(self, instance, owner):
if instance is None:
return self
return instance.__dict__[self._name]
def validate(self, value):
for validation in self.validations:
validation(value)
def __set__(self, instance, value):
self.validate(value)
instance.__dict__[self._name] = value
class ClientClass:
descriptor = Field(
Validation(lambda x: isinstance(x, (int, float)), "is not a number"),
Validation(lambda x: x >= 0, "is not >= 0")
)
We can see this object in action in the following listing:
>>> client = ClientClass()
>>> client.descriptor = 42
>>> client.descriptor
42
>>> client.descriptor = -42
Traceback (most recent call last):
...
ValueError: -42 is not >= 0
>>> client.descriptor = "invalid value"
...
ValueError: 'invalid value' is not a number
The idea is that something that we would normally place in a property can be abstracted
away into a descriptor, and reuse it multiple times. In this case, the __set__() method
would be doing what the @property.setter would have been doing.
1.2.3. __delete__(self, instance)¶
This method is called upon with the following statement, in which self would be the
descriptor attribute, and instance would be the client object in this example:
>>> del client.descriptor
In the following example, we use this method to create a descriptor with the goal of preventing you from removing attributes from an object without the required administrative privileges. Notice how, in this case, that the descriptor has logic that is used to predicate with the values of the object that is using it, instead of different related objects:
class ProtectedAttribute:
def __init__(self, requires_role=None) -> None:
self.permission_required = requires_role
self._name = None
def __set_name__(self, owner, name):
self._name = name
def __set__(self, user, value):
if value is None:
raise ValueError(f"{self._name} can't be set to None")
user.__dict__[self._name] = value
def __delete__(self, user):
if self.permission_required in user.permissions:
user.__dict__[self._name] = None
else:
raise ValueError(f"User {user!s} doesn't have {self.permission_required} permission")
class User:
"""Only users with "admin" privileges can remove their email
address."""
email = ProtectedAttribute(requires_role="admin")
def __init__(self, username: str, email: str, permission_list: list = None) -> None:
self.username = username
self.email = email
self.permissions = permission_list or []
def __str__(self):
return self.username
Before seeing examples of how this object works, it’s important to remark some of the
criteria of this descriptor. Notice the User class requires the username and email as
mandatory parameters. According to its __init__ method, it cannot be a user if it doesn’t
have an email attribute. If we were to delete that attribute, and extract it from the object
entirely we would be creating an inconsistent object, with some invalid intermediate state
that does not correspond to the interface defined by the class User. Details like this one are
really important, in order to avoid issues. Some other object is expecting to work with this
User, and it also expects that it has an email attribute.
For this reason, it was decided that the “deletion” of an email will just simply set it to None. For the same reason, we must forbid
someone trying to set a None value to it, because that would bypass the mechanism we placed in the __delete__ method.
Here, we can see it in action, assuming a case where only users with “admin” privileges can remove their email address:
>>> admin = User("root", "root@d.com", ["admin"])
>>> user = User("user", "user1@d.com", ["email", "helpdesk"])
>>> admin.email
'root@d.com'
>>> del admin.email
>>> admin.email is None
True
>>> user.email
'user1@d.com'
>>> user.email = None
ValueError: email can't be set to None
>>> del user.email
ValueError: User user doesn't have admin permission
Here, in this simple descriptor, we see that we can delete the email from users that
contain the “admin” permission only. As for the rest, when we try to call del on that
attribute, we will get a ValueError exception.
In general, this method of the descriptor is not as commonly used as the two previous ones, but it is worth showing it for completeness.
1.2.4. __set_name__(self, owner, name)¶
When we create the descriptor object in the class that is going to use it, we generally need the descriptor to know the name of the attribute it is going to be handling.
This attribute name is the one we use to read from and write to __dict__ in the __get__
and __set__ methods, respectively.
Before Python 3.6, the descriptor couldn’t take this name automatically, so the most general approach was to just pass it explicitly when initializing the object. This works fine, but it has an issue in that it requires that we duplicate the name every time we want to use the descriptor for a new attribute.
This is what a typical descriptor would look like if we didn’t have this method:
class DescriptorWithName:
def __init__(self, name):
self.name = name
def __get__(self, instance, value):
if instance is None:
return self
logger.info("getting %r attribute from %r", self.name, instance)
return instance.__dict__[self.name]
def __set__(self, instance, value):
instance.__dict__[self.name] = value
class ClientClass:
descriptor = DescriptorWithName("descriptor")
We can see how the descriptor uses this value:
>>> client = ClientClass()
>>> client.descriptor = "value"
>>> client.descriptor
INFO:getting 'descriptor' attribute from <ClientClass object at 0x...>
'value'
Now, if we wanted to avoid writing the name of the attribute twice (once for the variable assigned inside the class, and once again as the name of the first parameter of the descriptor), we have to resort to a few tricks, like using a class decorator, or (even worse) using a metaclass.
In Python 3.6, the new method __set_name__ was added, and it receives the class where
that descriptor is being created, and the name that is being given to that descriptor. The
most common idiom is to use this method for the descriptor so that it can store the required
name in this method.
For compatibility, it is generally a good idea to keep a default value in the __init__
method but still take advantage of __set_name__.
With this method, we can rewrite the previous descriptors as follows:
class DescriptorWithName:
def __init__(self, name=None):
self.name = name
def __set_name__(self, owner, name):
self.name = name
...
2. Types of descriptors¶
Based on the methods we have just explored, we can make an important distinction among descriptors in terms of how they work. Understanding this distinction plays an important role in working effectively with descriptors, and will also help to avoid caveats or common errors at runtime.
If a descriptor implements the __set__ or __delete__ methods, it is called a data
descriptor. Otherwise, a descriptor that solely implements __get__ is a non-data
descriptor. Notice that __set_name__ does not affect this classification at all.
When trying to resolve an attribute of an object, a data descriptor will always take precedence over the dictionary of the object, whereas a non-data descriptor will not. This means that in a non-data descriptor if the object has a key on its dictionary with the same name as the descriptor, this one will always be called, and the descriptor itself will never run. Conversely, in a data descriptor, even if there is a key in the dictionary with the same name as the descriptor, this one will never be used since the descriptor itself will always end up being called.
The following two sections explain this in more detail, with examples, in order to get a deeper idea of what to expect from each type of descriptor.
2.1. Non-data descriptors¶
We will start with a descriptor that only implements the __get__ method, and see how
it is used:
class NonDataDescriptor:
def __get__(self, instance, owner):
if instance is None:
return self
return 42
class ClientClass:
descriptor = NonDataDescriptor()
As usual, if we ask for the descriptor, we get the result of its __get__ method:
>>> client = ClientClass()
>>> client.descriptor
42
But if we change the descriptor attribute to something else, we lose access to this value, and get what was assigned to it instead:
>>> client.descriptor = 43
>>> client.descriptor
43
Now, if we delete the descriptor, and ask for it again, let’s see what we get:
>>> del client.descriptor
>>> client.descriptor
42
Let’s rewind what just happened. When we first created the client object, the descriptor attribute lay in the class, not the instance, so if we ask for the dictionary of the client object, it will be empty:
>>> vars(client)
{}
And then, when we request the .descriptor attribute, it doesn’t find any key in
client.__dict__ named “descriptor”, so it goes to the class, where it will find it, but
only as a descriptor, hence why it returns the result of the __get__ method.
But then, we change the value of the .descriptor attribute to something else, and what
this does is set this into the dictionary of the instance, meaning that this time it won’t be
empty:
>>> client.descriptor = 99
>>> vars(client)
{'descriptor': 99}
So, when we ask for the .descriptor attribute here, it will look for it in the object (and
this time it will find it, because there is a key named descriptor in the __dict__ attribute
of the object, as the vars result is showing us), and return it without having to look for it in
the class. For this reason, the descriptor protocol is never invoked, and the next time we ask
for this attribute, it will instead return the value we have overridden it with (99).
Afterward, we delete this attribute by calling del, and what this does is remove the key
“descriptor” from the dictionary of the object, leaving us back in the first scenario, where
it’s going to default to the class where the descriptor protocol will be activated:
>>> del client.descriptor
>>> vars(client)
{}
>>> client.descriptor
42
This means that if we set the attribute of the descriptor to something else, we might be accidentally breaking it. Why? Because the descriptor doesn’t handle the delete action (some of them don’t need to).
This is called a non-data descriptor because it doesn’t implement the __set__ magic
method, as we will see in the next example.
2.2. Data descriptors¶
Now, let’s look at the difference of using a data descriptor. For this, we are going to create
another simple descriptor that implements the __set__ method:
class DataDescriptor:
def __get__(self, instance, owner):
if instance is None:
return self
return 42
def __set__(self, instance, value):
logger.debug("setting %s.descriptor to %s", instance, value)
instance.__dict__["descriptor"] = value
class ClientClass:
descriptor = DataDescriptor()
Let’s see what the value of the descriptor returns:
>>> client = ClientClass()
>>> client.descriptor
42
Now, let’s try to change this value to something else, and see what it returns instead:
>>> client.descriptor = 99
>>> client.descriptor
42
The value returned by the descriptor didn’t change. But when we assign a different value to it, it must be set to the dictionary of the object (as it was previously):
>>> vars(client)
{'descriptor': 99}
>>> client.__dict__["descriptor"]
99
So, the __set__() method was called, and indeed it did set the value to the dictionary of
the object, only this time, when we request this attribute, instead of using the __dict__
attribute of the dictionary, the descriptor takes precedence (because it’s an overriding
descriptor ).
One more thing: deleting the attribute will not work anymore:
>>> del client.descriptor
Traceback (most recent call last):
...
AttributeError: __delete__
The reason is as follows: given that now, the descriptor always takes place, calling
del on an object doesn’t try to delete the attribute from the dictionary (__dict__) of the
object, but instead it tries to call the __delete__() method of the descriptor (which is
not implemented in this example, hence the attribute error).
This is the difference between data and non-data descriptors. If the descriptor implements
__set__(), then it will always take precedence, no matter what attributes are present in
the dictionary of the object. If this method is not implemented, then the dictionary will be
looked up first, and then the descriptor will run.
An interesting observation you might have noticed is this line on the set method:
instance.__dict__["descriptor"] = value. There are a lot of things to question about that line, but let’s
break it down into parts.
First, why is it altering just the name of a “descriptor” attribute? This is just a simplification for this example, but, as it transpires when working with descriptors, it doesn’t know at this point the name of the parameter it was assigned to, so we just used the one from the example, knowing that it was going to be “descriptor”.
In a real example, you would do one of two things: either receive the name as a parameter
and store it internally in the init method, so that this one will just use the internal
attribute, or, even better, use the __set_name__ method.
Why is it accessing the __dict__ attribute of the instance directly? Another good question,
which also has at least two explanations. First, you might be thinking why not just do the
following: setattr(instance, "descriptor", value). Remember that this method (__set__)
is called when we try to assign something to the
attribute that is a descriptor. So, using setattr() will call this descriptor again,
which, in turn, will call it again, and so on and so forth. This will end up in an infinite
recursion.
Note
Do not use setattr() or the assignment expression directly on the descriptor inside the __set__ method because that will trigger an infinite recursion.
Why, then, is the descriptor not able to book-keep the values of the properties for all of its objects?
The client class already has a reference to the descriptor. If we add a reference from the descriptor to the client object, we are creating circular dependencies, and these objects will never be garbage-collected. Since they are pointing at each other, their reference counts will never drop below the threshold for removal.
A possible alternative here is to use weak references, with the weakref module, and create
a weak reference key dictionary if we want to do that. This implementation is explained
later on, but we prefer to use this idiom, since it is fairly common and accepted when writing descriptors.
3. Descriptors in action¶
Now that we have seen what descriptors are, how they work, and what the main ideas behind them are, we can see them in action. In this section, we will be exploring some situations that can be elegantly addressed through descriptors.
Here, we will look at some examples of working with descriptors, and we will also cover implementation considerations for them (different ways of creating them, with their pros and cons), and finally we will discuss what are the most suitable scenarios for descriptors.
3.1. An application of descriptors¶
We will start with a simple example that works, but that will lead to some code duplication. It is not very clear how this issue will be addressed. Later on, we will devise a way of abstracting the repeated logic into a descriptor, which will address the duplication problem, and we will notice that the code on our client classes will be reduced drastically.
3.1.1. A first attempt without using descriptors¶
The problem we want to solve now is that we have a regular class with some attributes, but we wish to track all of the different values a particular attribute has over time, for example, in a list. The first solution that comes to our mind is to use a property, and every time a value is changed for that attribute in the setter method of the property, we add it to an internal list that will keep this trace as we want it.
Imagine that our class represents a traveler in our application that has a current city, and we want to keep track of all the cities that user has visited throughout the running of the program. The following code is a possible implementation that addresses these requirements:
class Traveller:
def __init__(self, name, current_city):
self.name = name
self._current_city = current_city
self._cities_visited = [current_city]
@property
def current_city(self):
return self._current_city
@current_city.setter
def current_city(self, new_city):
if new_city != self._current_city:
self._cities_visited.append(new_city)
self._current_city = new_city
@property
def cities_visited(self):
return self._cities_visited
We can easily check that this code works according to our requirements:
>>> alice = Traveller("Alice", "Barcelona")
>>> alice.current_city = "Paris"
>>> alice.current_city = "Brussels"
>>> alice.current_city = "Amsterdam"
>>> alice.cities_visited
['Barcelona', 'Paris', 'Brussels', 'Amsterdam']
So far, this is all we need and nothing else has to be implemented. For the purposes of this problem, the property would be more than enough. What happens if we need the exact same logic in multiple places of the application? This would mean that this is actually an instance of a more generic problem: tracing all the values of an attribute in another one. What would happen if we want to do the same with other attributes, such as keeping track of all tickets Alice bought, or all the countries she has been in? We would have to repeat the logic in all of these places.
Moreover, what would happen if we need this same behavior in different classes? We would have to repeat the code or come up with a generic solution (maybe a decorator, a property builder, or a descriptor).
3.1.2. The idiomatic implementation¶
We will now look at how to address the questions of the previous section by using a descriptor that is generic enough as to be applied in any class. Again, this example is not really needed because the requirements do not specify such generic behavior (we haven’t even followed the rule of three instances of the similar pattern previously creating the abstraction), but it is shown with the goal of portraying descriptors in action.
Note
Do not implement a descriptor unless there is actual evidence of the repetition we are trying to solve, and the complexity is proven to have paid off.
Now, we will create a generic descriptor that, given a name for the attribute to hold the traces of another one, will store the different values of the attribute in a list.
As we mentioned previously, the code is more than what we need for the problem, but its intention is just to show how a descriptor would help us in this case. Given the generic nature of descriptors, the reader will notice that the logic on it (the name of their method, and attributes) does not relate to the domain problem at hand (a traveler object). This is because the idea of the descriptor is to be able to use it in any type of class, probably on different projects, with the same outcomes.
In order to address this gap, some parts of the code are annotated, and the respective explanation for each section (what it does, and how it relates to the original problem) is described in the following code:
class HistoryTracedAttribute:
def __init__(self, trace_attribute_name) -> None:
self.trace_attribute_name = trace_attribute_name # [1]
self._name = None
def __set_name__(self, owner, name):
self._name = name
def __get__(self, instance, owner):
if instance is None:
return self
return instance.__dict__[self._name]
def __set__(self, instance, value):
self._track_change_in_value_for_instance(instance, value)
instance.__dict__[self._name] = value
def _track_change_in_value_for_instance(self, instance, value):
self._set_default(instance) # [2]
if self._needs_to_track_change(instance, value):
instance.__dict__[self.trace_attribute_name].append(value)
def _needs_to_track_change(self, instance, value) -> bool:
try:
current_value = instance.__dict__[self._name]
except KeyError: # [3]
return True
return value != current_value # [4]
def _set_default(self, instance):
instance.__dict__.setdefault(self.trace_attribute_name, []) # [6]
class Traveller:
current_city = HistoryTracedAttribute("cities_visited") # [1]
def __init__(self, name, current_city):
self.name = name
self.current_city = current_city # [5]
Some annotations and comments on the code are as follows (numbers in the list correspond to the number annotations in the previous listing):
The name of the attribute is one of the variables assigned to the descriptor, in this case,
current_city. We pass to the descriptor the name of the variable in which it will store the trace for the variable of the descriptor. In this example, we are telling our object to keep track of all the values thatcurrent_cityhas had in the attribute namedcities_visited.The first time we call the descriptor, in the
init, the attribute for tracing values will not exist, in which case we initialize it to an empty list to later append values to it.In the
initmethod, the name of the attributecurrent_citywill not exist either, so we want to keep track of this change as well. This is the equivalent of initializing the list with the first value in the previous example.Only track changes when the new value is different from the one that is currently set.
In the
init method, the descriptor already exists, and this assignment instruction triggers the actions from step 2 (create the empty list to start tracking values for it), and step 3 (append the value to this list, and set it to the key in the object for retrieval later).The
setdefaultmethod in a dictionary is used to avoid aKeyError. In this case an empty list will be returned for those attributes that aren’t still available.
It is true that the code in the descriptor is rather complex. On the other hand, the code in the client class is considerably simpler. Of course, this balance only pays off if we are going to use this descriptor multiple times, which is a concern we have already covered.
What might not be so clear at this point is that the descriptor is indeed completely independent from the client class. Nothing in it suggests anything about the business logic. This makes it perfectly suitable to apply it in any other class; even if it does something completely different, the descriptor will take the same effect.
This is the true Pythonic nature of descriptors. They are more appropriate for defining libraries, frameworks, or internal APIs, and not that much for business logic.
3.2. Different forms of implementing descriptors¶
We have to first understand a common issue that’s specific to the nature of descriptors before thinking of ways of implementing them. First, we will discuss the problem of a global shared state, and afterward we will move on and look at different ways descriptors can be implemented while taking this into consideration.
3.3. More considerations about descriptors¶
Here, we will discuss general considerations about descriptors in terms of what we can do with them when it is a good idea to use them, and also how things that we might have initially conceived as having been resolved by means of another approach can be improved through descriptors. We will then analyze the pros and cons of the original implementation versus the one after descriptors have been used.
3.3.1. Reusing code¶
Descriptors are a generic tool and a powerful abstraction that we can use to avoid code duplication. The best way to decide when to use descriptors is to identify cases where we would be using a property (whether for its get logic, set logic, or both), but repeating its structure many times.
Properties are just a particular case of descriptors (the @property decorator is a descriptor that implements the full descriptor protocol to define their get, set, and delete actions), which means that we can use descriptors for far more complex tasks.
Another powerful type we have seen for reusing code was decorators. Descriptors can help us create to better decorators by making sure that they will be able to work correctly for class methods as well.
When it comes to decorators, we could say that it is safe to always implement the
__get__() method on them, and also make it a descriptor. When trying to decide whether
the decorator is worth creating, consider the problems but note that there are no extra considerations
toward descriptors.
As for generic descriptors, besides the aforementioned three instances rule that applies to decorators (and, in general, any reusable component), it is advisable to also keep in mind that you should use descriptors for cases when we want to define an internal API, which is some code that will have clients consuming it. This is a feature-oriented more toward designing libraries and frameworks, rather than one-time solutions.
Unless there is a very good reason to, or that the code will look significantly better, we should avoid putting business logic in a descriptor. Instead, the code of a descriptor will contain more implementational code rather than business code. It is more similar to defining a new data structure or object that another part of our business logic will use as a tool.
Note
In general, descriptors will contain implementation logic, and not so much business logic.
3.3.2. Avoiding class decorators¶
If we recall the class decorator we used previously to determine how an event object is going to be serialized, we ended up with an implementation that (for Python 3.7+) relied on two class decorators:
@Serialization(
username=show_original,
password=hide_field,
ip=show_original,
timestamp=format_time
)
@dataclass
class LoginEvent:
username: str
password: str
ip: str
timestamp: datetime
The first one takes the attributes from the annotations to declare the variables, whereas the second one defines how to treat each file. Let’s see whether we can change these two decorators for descriptors instead.
The idea is to create a descriptor that will apply the transformation over the values of each attribute, returning the modified version according to our requirements (for example, hiding sensitive information, and formatting dates correctly):
from functools import partial
from typing import Callable
class BaseFieldTransformation:
def __init__(self, transformation: Callable[[], str]) -> None:
self._name = None
self.transformation = transformation
def __get__(self, instance, owner):
if instance is None:
return self
raw_value = instance.__dict__[self._name]
return self.transformation(raw_value)
def __set_name__(self, owner, name):
self._name = name
def __set__(self, instance, value):
instance.__dict__[self._name] = value
ShowOriginal = partial(BaseFieldTransformation, transformation=lambda x: x)
HideField = partial(
BaseFieldTransformation, transformation=lambda x: "**redacted**"
)
FormatTime = partial(
BaseFieldTransformation,
transformation=lambda ft: ft.strftime("%Y-%m-%d %H:%M"),
)
This descriptor is interesting. It was created with a function that takes one argument and returns one value. This function will be the transformation we want to apply to the field. From the base definition that defines generically how it is going to work, the rest of the descriptor classes are defined, simply by changing the particular function each one needs.
The example uses functools.partial as a way of simulating sub-classes, by applying a
partial application of the transformation function for that class, leaving a new callable that
can be instantiated directly.
In order to keep the example simple, we will implement the __init__() and
serialize() methods, although they could be abstracted away as well. Under these
considerations, the class for the event will now be defined as follows:
class LoginEvent:
username = ShowOriginal()
password = HideField()
ip = ShowOriginal()
timestamp = FormatTime()
def __init__(self, username, password, ip, timestamp):
self.username = username
self.password = password
self.ip = ip
self.timestamp = timestamp
def serialize(self):
return {
"username": self.username,
"password": self.password,
"ip": self.ip,
"timestamp": self.timestamp,
}
We can see how the object behaves at runtime:
>>> le = LoginEvent("john", "secret password", "1.1.1.1",
datetime.utcnow())
>>> vars(le)
{'username': 'john', 'password': 'secret password', 'ip': '1.1.1.1',
'timestamp': ...}
>>> le.serialize()
{'username': 'john', 'password': '**redacted**', 'ip': '1.1.1.1',
'timestamp': '...'}
>>> le.password
'**redacted**'
There are some differences with respect to the previous implementation that used a
decorator. This example added the serialize() method and hid the fields before
presenting them to its resulting dictionary, but if we asked for any of these attributes to an
instance of the event in memory at any point, it would still give us the original value,
without any transformation applied to it (we could have chosen to apply the
transformation when setting the value, and return it directly on the __get__(), as well).
Depending on the sensitivity of the application, this may or may not be acceptable, but in
this case, when we ask the object for its public attributes, the descriptor will apply the
transformation before presenting the results. It is still possible to access the original values
by asking for the dictionary of the object (by accessing __dict__), but when we ask for the
value, by default, it will return it converted.
In this example, all descriptors follow a common logic, which is defined in the base class. The descriptor should store the value in the object and then ask for it, applying the transformation it defines. We could create a hierarchy of classes, each one defining its own conversion function, in a way that the template method design pattern works. In this case, since the changes in the derived classes are relatively small (just one function), we opted for creating the derived classes as partial applications of the base class. Creating any new transformation field should be as simple as defining a new class that will be the base class, which is partially applied with the function we need. This can even be done ad hoc, so there might be no need to set a name for it.
Regardless of this implementation, the point is that since descriptors are objects, we can create models, and apply all rules of object-oriented programming to them. Design patterns also apply to descriptors. We could define our hierarchy, set the custom behavior, and so on. This example follows the OCP, because adding a new type of conversion method would just be about creating a new class, derived from the base one with the function it needs, without having to modify the base class itself (to be fair, the previous implementation with decorators was also OCP- compliant, but there were no classes involved for each transformation mechanism).
Let’s take an example where we create a base class that implements the __init__()``and
``serialize() methods so that we can define the LoginEvent class simply by deriving
from it, as follows:
class LoginEvent(BaseEvent):
username = ShowOriginal()
password = HideField()
ip = ShowOriginal()
timestamp = FormatTime()
Once we achieve this code, the class looks cleaner. It only defines the attributes it needs, and its logic can be quickly analyzed by looking at the class for each attribute. The base class will abstract only the common methods, and the class of each event will look simpler and more compact.
Not only do the classes for each event look simple, but the descriptor itself is very compact and a lot simpler than the class decorators. The original implementation with class decorators was good, but descriptors made it even better.
4. Analysis of descriptors¶
We have seen how descriptors work so far and explored some interesting situations in which they contribute to clean design by simplifying their logic and leveraging more compact classes.
Up to this point, we know that by using descriptors, we can achieve cleaner code, abstracting away repeated logic and implementation details. But how do we know our implementation of the descriptors is clean and correct? What makes a good descriptor? Are we using this tool properly or over-engineering with it?
4.1. How Python uses descriptors internally¶
Referring to the question as to what makes a good descriptor?, a simple answer would be that a good descriptor is pretty much like any other good Python object. It is consistent with Python itself. The idea that follows this premise is that analyzing how Python uses descriptors will give us a good idea of good implementations so that we know what to expect from the descriptors we write.
We will see the most common scenarios where Python itself uses descriptors to solve parts of its internal logic, and we will also discover elegant descriptors and that they have been there in plain sight all along.
4.1.1. Functions and methods¶
The most resonating case of an object that is a descriptor is probably a function. Functions
implement the __get__ method, so they can work as methods when defined inside a class.
Methods are just functions that take an extra argument. By convention, the first argument
of a method is named “self”, and it represents an instance of the class that the method is
being defined in. Then, whatever the method does with “self”, would be the same as any
other function receiving the object and applying modifications to it.
In order words, when we define something like this:
class MyClass:
def method(self, ...):
self.x = 1
It is actually the same as if we define this:
class MyClass:
pass
def method(myclass_instance, ...):
myclass_instance.x = 1
method(MyClass())
So, it is just another function, modifying the object, only that it’s defined inside the class, and it is said to be bound to the object.
When we call something in the form of this:
instance = MyClass()
instance.method(...)
Python is, in fact, doing something equivalent to this:
instance = MyClass()
MyClass.method(instance, ...)
Notice that this is just a syntax conversion that is handled internally by Python. The way this works is by means of descriptors.
Since functions implement the descriptor protocol (see the following listing) before calling
the method, the __get__() method is invoked first, and some transformations happen
before running the code on the internal callable:
>>> def function(): pass
...
>>> function.__get__
<method-wrapper '__get__' of function object at 0x...>
In the instance.method(...) statement, before processing all the arguments of the
callable inside the parenthesis, the “instance.method” part is evaluated.
Since method is an object defined as a class attribute, and it has a __get__ method, this is
called. What this does is convert the function to a method, which means binding the
callable to the instance of the object it is going to work with.
Let’s see this with an example so that we can get an idea of what Python might be doing internally.
We will define a callable object inside a class that will act as a sort of function or method
that we want to define to be invoked externally. An instance of the Method class is
supposed to be a function or method to be used inside a different class. This function will
just print its three parameters: the instance that it received (which would be the
self parameter on the class it’s being defined in), and two more arguments. Notice that in
the __call__() method, the self parameter does not represent the instance of
MyClass, but instead an instance of Method. The parameter named instance is meant to
be a MyClass type of object:
class Method:
def __init__(self, name):
self.name = name
def __call__(self, instance, arg1, arg2):
print(f"{self.name}: {instance} called with {arg1} and {arg2}")
class MyClass:
method = Method("Internal call")
Under these considerations and, after creating the object, the following two calls should be equivalent, based on the preceding definition:
instance = MyClass()
Method("External call")(instance, "first", "second")
instance.method("first", "second")
However, only the first one works as expected, as the second one gives an error:
Traceback (most recent call last):
File "file", line, in <module>
instance.method("first", "second")
TypeError: __call__() missing 1 required positional argument: 'arg2'
We are seeing the same error we faced with a decorator. The arguments are being shifted to the left by one,
instance is taking the place of self, arg1 is going to be instance, and there is nothing to provide
for arg2.
In order to fix this, we need to make Method a descriptor.
This way, when we call instance.method first, we are going to call its __get__(), on
which we bind this callable to the object accordingly (bypassing the object as the first
parameter), and then proceed:
from types import MethodType
class Method:
def __init__(self, name):
self.name = name
def __call__(self, instance, arg1, arg2):
print(f"{self.name}: {instance} called with {arg1} and {arg2}")
def __get__(self, instance, owner):
if instance is None:
return self
return MethodType(self, instance)
Now, both calls work as expected:
External call: <MyClass object at 0x...> called with fist and second
Internal call: <MyClass object at 0x...> called with first and second
What we did is convert the function (actually the callable object we defined instead) to a
method by using MethodType from the types module. The first parameter of this class
should be a callable (self, in this case, is one by definition because it implements
__call__), and the second one is the object to bind this function to.
Something similar to this is what function objects use in Python so they can work as methods when they are defined inside a class.
Since this is a very elegant solution, it’s worth exploring it to keep it in mind as a Pythonic approach when defining our own objects. For instance, if we were to define our own callable, it would be a good idea to also make it a descriptor so that we can use it in classes as class attributes as well.
4.1.2. Built-in decorators for methods¶
All @property, @classmethod, and @staticmethod decorators are descriptors.
We have mentioned several times that the idiom makes the descriptor return itself when it’s being called from a class directly. Since properties are actually descriptors, that is the reason why, when we ask it from the class, we don’t get the result of computing the property, but the entire property object instead:
>>> class MyClass:
... @property
... def prop(self): pass
...
>>> MyClass.prop
<property object at 0x...>
For class methods, the __get__ function in the descriptor will make sure that the class is
the first parameter to be passed to the function being decorated, regardless of whether it’s
called from the class directly or from an instance. For static methods, it will make sure that
no parameters are bound other than those defined by the function, namely undoing the
binding done by __get__() on functions that make self the first parameter of that
function.
Let’s take an example; we create a @classproperty decorator that works as the regular
@property decorator, but for classes instead. With a decorator like this one, the following
code should be able to work:
class TableEvent:
schema = "public"
table = "user"
@classproperty
def topic(cls):
prefix = read_prefix_from_config()
return f"{prefix}{cls.schema}.{cls.table}"
>>> TableEvent.topic
'public.user'
>>> TableEvent().topic
'public.user'
4.2. Implementing descriptors in decorators¶
We now understand how Python uses descriptors in functions to make them work as
methods when they are defined inside a class. We have also seen examples of cases where
we can make decorators work by making them comply with the descriptor protocol by
using the __get__() method of the interface to adapt the decorator to the object it is being
called with. This solves the problem for our decorators in the same way that Python solves
the issue of functions as methods in objects.
The general recipe for adapting a decorator in such a way is to implement the __get__()
method on it and use types.MethodType to convert the callable (the decorator itself) to a
method bound to the object it is receiving (the instance parameter received by __get__).
For this to work, we will have to implement the decorator as an object, because otherwise, if
we are using a function, it will already have a __get__() method, which will be doing
something different that will not work unless we adapt it. The cleaner way to proceed is to
define a class for the decorator.
Note
Use a decorator class when defining a decorator that we want to apply to class methods, and implement the __get__() method on it.