General traits of good code¶
1. Design by contract¶
Some parts of the software we are working on are not meant to be called directly by users, but instead by other parts of the code. Such is the case when we divide the responsibilities of the application into different components or layers, and we have to think about the interaction between them.
We will have to encapsulate some functionality behind each component, and expose an interface to clients who are going to use that functionality, namely an Application Programming Interface (API). The functions, classes, or methods we write for that component have a particular way of working under certain considerations that, if they are not met, will make our code crash. Conversely, clients calling that code expect a particular response, and any failure of our function to provide this would represent a defect. That is to say that if, for example, we have a function that is expected to work with a series of parameters of type integers, and some other function invokes our passing strings, it is clear that it should not work as expected, but in reality, the function should not run at all because it was called incorrectly (the client made a mistake). This error should not pass silently.
Of course, when designing an API, the expected input, output, and side-effects should be documented. But documentation cannot enforce the behavior of the software at runtime. These rules, what every part of the code expects in order to work properly and what the caller is expecting from them, should be part of the design, and here is where the concept of a contract comes into place.
The idea behind the DbC is that instead of implicitly placing in the code what every party is expecting, both parties agree on a contract that, if violated, will raise an exception, clearly stating why it cannot continue.
In our context, a contract is a construction that enforces some rules that must be honored during the communication of software components. A contract entails mainly preconditions and postconditions, but in some cases, invariants, and side-effects are also described:
Preconditions: We can say that these are all the checks code will do before running. It will check for all the conditions that have to be made before the function can proceed. In general, it’s implemented by validating the data set provided in the parameters passed, but nothing should stop us from running all sorts of validations (for example, validating a set in a database, a file, another method that was called before, and so on) if we consider that their side-effects are overshadowed by the importance of such a validation. Notice that this imposes a constraint on the caller.
Postconditions: The opposite of preconditions, here, the validations are done after the function call is returned. Postcondition validations are run to validate what the caller is expecting from this component.
Invariants: Optionally, it would be a good idea to document, in the docstring of a function, the invariants, the things that are kept constant while the code of the function is running, as an expression of the logic of the function to be correct.
Side-effects: Optionally, we can mention any side-effects of our code in the docstring.
While conceptually all of these items form part of the contract for a software component, and this is what should go to the documentation of such piece, only the first two (preconditions and postconditions) are to be enforced at a low level (code).
The reason why we would design by contract is that if errors occur, they must be easy to spot (and by noticing whether it was either the precondition or postcondition that failed, we will find the culprit much easily) so that they can be quickly corrected. More importantly, we want critical parts of the code to avoid being executed under the wrong assumptions. This should help to clearly mark the limits for the responsibilities and errors if they occur, as opposed to something saying—this part of the application is failing… But the caller code provided the wrong arguments, so where should we apply the fix?
The idea is that preconditions bind the client (they have an obligation to meet them if they want to run some part of the code), whereas postconditions bind the component in question to some guarantees that the client can verify and enforce.
This way, we can quickly identify responsibilities. If the precondition fails, we know it is due to a defect on the client. On the other hand, if the postcondition check fails, we know the problem is in the routine or class (supplier) itself.
Specifically regarding preconditions, it is important to highlight that they can be checked at runtime, and if they occur, the code that is being called should not be run at all (it does not make sense to run it because its conditions do not hold, and further more, doing so might end up making things worse).
1.1. Preconditions¶
Preconditions are all of the guarantees a function or method expects to receive in order to work correctly. In general programming terms, this usually means to provide data that is properly formed, for example, objects that are initialized, non-null values, and many more. For Python, in particular, being dynamically typed, this also means that sometimes we need to check for the exact type of data that is provided. This is not exactly the same as type checking, the kind mypy would do this, but rather verify for exact values that are needed.
Part of these checks can be detected early on by using static analysis tools, such as mypy, but these checks are not enough. A function should have proper validation for the information that it is going to handle.
Now, this poses the question of where to place the validation logic, depending on whether we let the clients validate all the data before calling the function, or allow this one to validate everything that it received prior running its own logic. The former corresponds to a tolerant approach (because the function itself is still allowing any data, potentially malformed data as well), whereas the latter corresponds to a demanding approach.
For the purposes of this analysis, we prefer a demanding approach when it comes to DbC, because it is usually the safest choice in terms of robustness, and usually the most common practice in the industry.
Regardless of the approach we decide to take, we should always keep in mind the non-redundancy principle, which states that the enforcement of each precondition for a function should be done by only one of the two parts of the contract, but not both. This means that we put the validation logic on the client, or we leave it to the function itself, but in no cases should we duplicate it (which also relates to the DRY principle).
1.2. Postconditions¶
Postconditions are the part of the contract that is responsible for enforcing the state after the method or function has returned.
Assuming that the function or method has been called with the correct properties (that is, with its preconditions met), then the postconditions will guarantee that certain properties are preserved.
The idea is to use postconditions to check and validate for everything that a client might need. If the method executed properly, and the postcondition validations pass, then any client calling that code should be able to work with the returned object without problems, as the contract has been fulfilled.
1.3. Pythonic contracts¶
Programming by Contract for Python, is deferred. This doesn’t mean that we cannot implement it in Python, because, as introduced at the beginningf, this is a general design principle.
Probably the best way to enforce this is by adding control mechanisms to our methods, functions, and classes, and if they fail raise a RuntimeError exception or ValueError . It’s hard to devise a general rule for the correct type of exception, as that would pretty much depend on the application in particular. These previously mentioned exceptions are the most common types of exception, but if they don’t fit accurately with the problem, creating a custom exception would be the best choice.
We would also like to keep the code as isolated as possible. That is, the code for the preconditions in one part, the one for the postconditions in another, and the core of the function separated. We could achieve this separation by creating smaller functions, but in some cases implementing a decorator would be an interesting alternative.
1.4. Conclusions¶
The main value of this design principle is to effectively identify where the problem is. By defining a contract, when something fails at runtime it will be clear what part of the code is broken, and what broke the contract.
As a result of following this principle, the code will be more robust. Each component is enforcing its own constraints and maintaining some invariants, and the program can be proven correct as long as these invariants are preserved.
It also serves the purpose of clarifying the structure of the program better. Instead of trying to run ad hoc validations, or trying to surmount all possible failure scenarios, the contracts explicitly specify what each function or method expects to work properly, and what is expected from them.
Of course, following these principles also adds extra work, because we are not just programming the core logic of our main application, but also the contracts. In addition, we might also want to consider adding unit tests for these contracts as well. However, the quality gained by this approach pays off in the long run; hence, it is a good idea to implement this principle for critical components of the application.
Nonetheless, for this method to be effective, we should carefully think about what are we willing to validate, and this has to be a meaningful value. For example, it would not make much sense to define contracts that only check for the correct data types of the parameters provided to a function. Many programmers would argue that this would be like trying to make Python a statically-typed language. Regardless of this, tools such as Mypy, in combination with the use of annotations, would serve this purpose much better and with less effort. With that in mind, design contracts so that there is actually value on them.
2. Defensive programming¶
Defensive programming follows a somewhat different approach than DbC; instead of stating all conditions that must be held in a contract, that if unmet will raise an exception and make the program fail, this is more about making all parts of the code (objects, functions, or methods) able to protect themselves against invalid inputs.
Defensive programming is a technique that has several aspects, and it is particularly useful if it is combined with other design principles (this means that the fact that it follows a different philosophy than DbC does not mean that it is a case of either one or the other—it could mean that they might complement each other).
The main ideas on the subject of defensive programming are how to handle errors for scenarios that we might expect to occur, and how to deal with errors that should never occur (when impossible conditions happen). The former will fall into error handling procedures, while the latter will be the case for assertions, both topics we will be exploring in the following sections.
2.1. Error handling¶
In our programs, we resort to error handling procedures for situations that we anticipate as prone to cause errors. This is usually the case for data input.
The idea behind error handling is to gracefully respond to these expected errors in an attempt to either continue our program execution or decide to fail if the error turns out to be insurmountable.
There are different approaches by which we can handle errors on our programs, but not all of them are always applicable. Some of these approaches are as follows:
Value substitution
Error logging
Exception handling
2.1.1. Value substitution¶
In some scenarios, when there is an error and there is a risk of the software producing an incorrect value or failing entirely, we might be able to replace the result with another, safer value. We call this value substitution, since we are in fact replacing the actual erroneous result for a value that is to be considered non-disruptive (it could be a default, a well-known constant, a sentinel value, or simply something that does not affect the result at all, like returning zero in a case where the result is intended to be applied to a sum).
Value substitution is not always possible, however. This strategy has to be carefully chosen for cases where the substituted value is actually a safe option. Making this decision is a trade-off between robustness and correctness. A software program is robust when it does not fail, even in the presence of an erroneous scenario. But this is not correct either. This might not be acceptable for some kinds of software. If the application is critical, or the data being handled is too sensitive, this is not an option, since we cannot afford to provide users (or other parts of the application) with erroneous results. In these cases, we opt for correctness, rather than let the program explode when yielding the wrong results.
A slightly different, and safer, version of this decision is to use default values for data that is not provided. This can be the case for parts of the code that can work with a default behavior, for example, default values for environment variables that are not set, for missing entries in configuration files, or for parameters of functions. We can find examples of Python supporting this throughout different methods of its API, for example, dictionaries have a get method, whose (optional) second parameter allows you to indicate a default value:
>>> configuration = {"dbport": 5432}
>>> configuration.get("dbhost", "localhost")
'localhost'
>>> configuration.get("dbport")
5432
Environment variables have a similar API:
>>> import os
>>> os.getenv("DBHOST")
'localhost'
>>> os.getenv("DPORT", 5432)
5432
In both previous examples, if the second parameter is not provided, None will be returned, because it’s the default value those functions are defined with. We can also define default values for the parameters of our own functions:
>>> def connect_database(host="localhost", port=5432):
...
logger.info("connecting to database server at %s:%i", host, port)
In general, replacing missing parameters with default values is acceptable, but substituting erroneous data with legal close values is more dangerous and can mask some errors. Take this criterion into consideration when deciding on this approach.
2.1.2. Exception handling¶
In the presence of incorrect or missing input data, sometimes it is possible to correct the situation with some examples such as the ones mentioned in the previous section. In other cases, however, it is better to stop the program from continuing to run with the wrong data than to leave it computing under erroneous assumptions. In those cases, failing and notifying the caller that something is wrong is a good approach, and this is the case for a precondition that was violated, as we saw in DbC.
Nonetheless, erroneous input data is not the only possible way in which a function can go wrong. After all, functions are not just about passing data around; they also have side-effects and connect to external components.
It could be possible that a fault in a function call is due to a problem on one of these external components, and not in our function itself. If that is the case, our function should communicate this properly. This will make it easier to debug. The function should clearly and unambiguously notify the rest of the application about errors that cannot be ignored so that they can be addressed accordingly.
The mechanism for accomplishing this is an exception. It is important to emphasize that this is what exceptions should be used for—clearly announcing an exceptional situation, not altering the flow of the program according to business logic.
If the code tries to use exceptions to handle expected scenarios or business logic, the flow of the program will become harder to read. This will lead to a situation where exceptions are used as a sort of go-to statement, that (to make things worse) could span multiple levels on the call stack (up to caller functions), violating the encapsulation of the logic into its correct level of abstraction. The case could get even worse if these except blocks are mixing business logic with truly exceptional cases that the code is trying to defend against; in that case, it will be harder to distinguish between the core logic we have to maintain and errors to be handled.
Note
Do not use exceptions as a go-to mechanism for business logic. Raise exceptions when there is actually something wrong with the code that callers need to be aware of.
This last concept is an important one; exceptions are usually about notifying the caller about something that is amiss. This means that exceptions should be used carefully because they weaken encapsulation. The more exceptions a function has, the more the caller function will have to anticipate, therefore knowing about the function it is calling. And if a function raises too many exceptions, this means that is not so context-free, because every time we want to invoke it, we will have to keep all of its possible side-effects in mind.
This can be used as a heuristic to tell when a function is not cohesive enough and has too many responsibilities. If it raises too many exceptions, it could be a sign that it has to be broken down into multiple, smaller ones.
2.1.2.1. Handle exceptions at the right level of abstraction¶
Exceptions are also part of the principal functions that do one thing, and one thing only. The exception the function is handling (or raising) has to be consistent with the logic encapsulated on it.
In this example, we can see what we mean by mixing different levels of abstractions. Imagine an object that acts as a transport for some data in our application. It connects to an external component where the data is going to be sent upon decoding. In the following listing, we will focus on the deliver_event method:
class DataTransport:
"""An example of an object handling exceptions of different levels."""
retry_threshold: int = 5
retry_n_times: int = 3
def __init__(self, connector):
self._connector = connector
self.connection = None
def deliver_event(self, event):
try:
self.connect()
data = event.decode()
self.send(data)
except ConnectionError as e:
logger.info(f"connection error detected: {e}")
raise
except ValueError as e:
logger.error(f"{event} contains incorrect data: {e}")
raise
def connect(self):
for _ in range(self.retry_n_times):
try:
self.connection = self._connector.connect()
except ConnectionError as e:
logger.info(f"{e}: attempting new connection in {self.retry_threshold}")
time.sleep(self.retry_threshold)
else:
return self.connection
raise ConnectionError(f"Couldn't connect after {self.retry_n_times} times")
def send(self, data):
return self.connection.send(data)
For our analysis, let’s zoom in and focus on how the deliver_event() method handles exceptions.
What does ValueError have to do with ConnectionError? Not much. By looking at these two highly
different types of error, we can get an idea of how responsibilities should be divided. The
ConnectionError should be handled inside the connect method. This will allow a clear separation of
behavior. For example, if this method needs to support retries, that would be a way of doing it. Conversely,
ValueError belongs to the decode method of the event. With this new implementation, this method does not
need to catch any exception: the exceptions it was worrying about before are either handled by internal
methods or deliberately left to be raised.
We should separate these fragments into different methods or functions. For connection management, a small function should be enough. This function will be in charge of trying to establish the connection, catching exceptions (should they occur), and logging them accordingly:
def connect_with_retry(connector, retry_n_times, retry_threshold=5):
"""Tries to establish the connection of <connector> retrying
<retry_n_times>.
If it can connect, returns the connection object.
If it's not possible after the retries, raises ConnectionError
:param connector: An object with a `.connect()` method.
:param retry_n_times int: The number of times to try to call
``connector.connect()``.
:param retry_threshold int: The time lapse between retry calls.
"""
for _ in range(retry_n_times):
try:
return connector.connect()
except ConnectionError as e:
logger.info(f"{e}: attempting new connection in {retry_threshold}")
time.sleep(retry_threshold)
exc = ConnectionError(f"Couldn't connect after {retry_n_times} times")
logger.exception(exc)
raise exc
Then, we will call this function in our method. As for the ValueError exception on the event, we could
separate it with a new object and do composition, but for this limited case it would be overkill, so just
moving the logic to a separate method would be enough. With these two considerations in place, the new version
of the method looks much more compact and easier to read:
class DataTransport:
"""An example of an object that separates the exception handling by
abstraction levels.
"""
retry_threshold: int = 5
retry_n_times: int = 3
def __init__(self, connector):
self._connector = connector
self.connection = None
def deliver_event(self, event):
self.connection = connect_with_retry(self._connector, self.retry_n_times, self.retry_threshold)
self.send(event)
def send(self, event):
try:
return self.connection.send(event.decode())
except ValueError as e:
logger.error(f"{event} contains incorrect data: {e}")
raise
2.1.2.2 Do not expose tracebacks¶
This is a security consideration. When dealing with exceptions, it might be acceptable to let them propagate if the error is too important, and maybe even let the program fail if this is the decision for that particular scenario and correctness was favored over robustness.
When there is an exception that denotes a problem, it’s important to log in with as much detail as possible (including the traceback information, message, and all we can gather) so that the issue can be corrected efficiently. At the same time, we want to include as much detail as possible for ourselves: we definitely don’t want any of this becoming visible to users.
In Python, tracebacks of exceptions contain very rich and useful debugging information. Unfortunately, this information is also very useful for attackers or malicious users who want to try and harm the application, not to mention that the leak would represent an important information disclosure, jeopardizing the intellectual property of your organization (parts of the code will be exposed).
If you choose to let exceptions propagate, make sure not to disclose any sensitive information. Also, if you have to notify users about a problem, choose generic messages (such as Something went wrong, or Page not found). This is a common technique used in web applications that display generic informative messages when an HTTP error occurs.
2.1.2.3 Avoid empty except blocks¶
This was even referred to as the most diabolical Python anti-pattern. While it is good to anticipate and defend our programs against some errors, being too defensive might lead to even worse problems. In particular, the only problem with being too defensive is that there is an empty except block that silently passes without doing anything.
Python is so flexible that it allows us to write code that can be faulty and yet, will not raise an error, like this:
try:
process_data()
except:
pass
The problem with this is that it will not fail, ever. Even when it should. It is also non-Pythonic if you remember from the zen of Python that errors should never pass silently.
If there is a true exception, this block of code will not fail, which might be what we wanted in the first place. But what if there is a defect? We need to know if there is an error in our logic to be able to correct it. Writing blocks such as this one will mask problems, making things harder to maintain.
There are two alternatives:
Catch a more specific exception (not too broad, such as an Exception). In fact, some linting tools and IDEs will warn you in some cases when the code is handling too broad an exception.
Do some actual error handling on the except block.
The best thing to do would be to apply both items simultaneously.
Handling a more specific exception (for example, AttributeError or KeyError) will make the program more maintainable because the reader will know what to expect, and can get an idea of the why of it. It will also leave other exceptions free to be raised, and if that happens, this probably means a bug, only this time it can be discovered.
Handling the exception itself can mean multiple things. In its simplest form, it could be just about logging the exception (make sure to use logger.exception or logger.error to provide the full context of what happened). Other alternatives could be to return a default value (substitution, only that in this case after detecting an error, not prior to causing it), or raising a different exception.
Note
If you choose to raise a different exception, to include the original exception that caused the problem, which leads us to the next point.
2.1.2.4. Include the original exception¶
As part of our error handling logic, we might decide to raise a different one, and maybe even change its message. If that is the case, it is recommended to include the original exception that led to that.
In Python 3, we can now use the raise <e> from <original_exception> syntax. When using this construction, the
original traceback will be embedded into the new exception, and the original exception will be set in the
__cause__ attribute of the resulting one.
For example, if we desire to wrap default exceptions with custom ones internally to our project, we could still do that while including information about the root exception:
class InternalDataError(Exception):
"""An exception with the data of our domain problem."""
def process(data_dictionary, record_id):
try:
return data_dictionary[record_id]
except KeyError as e:
raise InternalDataError("Record not present") from e
Note
Always use the raise <e> from <o> syntax when changing the type of the exception.
2.2. Using assertions in Python¶
Assertions are to be used for situations that should never happen, so the expression on the assert statement has to mean an impossible condition. Should this condition happen, it means there is a defect in the software.
In contrast with the error handling approach, here there is (or should not be) a possibility of continuing the program. If such an error occurs, the program must stop. It makes sense to stop the program because, as commented before, we are in the presence of a defect, so there is no way to move forward by releasing a new version of the software that corrects this defect.
The idea of using assertions is to prevent the program from causing further damage if such an invalid scenario is presented. Sometimes, it is better to stop and let the program crash, rather than let it continue processing under the wrong assumptions.
For this reason, assertions should not be mixed with the business logic, or used as control flow mechanisms for the software. The following example is a bad idea:
try:
assert condition.holds(), "Condition is not satisfied"
except AssertionError:
alternative_procedure()
Note
Do not catch the AssertionError exception.
Make sure that the program terminates when an assertion fails.
Include a descriptive error message in the assertion statement and log the errors to make sure that you can properly debug and correct the problem later on.
Another important reason why the previous code is a bad idea is that besides catching AssertionError, the statement in the assertion is a function call. Function calls can have side-effects, and they aren’t always repeatable (we don’t know if calling condition.holds() again will yield the same result). Moreover, if we stop the debugger at that line, we might not be able to conveniently see the result that causes the error, and, again, even if we call that function again, we don’t know if that was the offending value.
A better alternative requires fewer lines of code and provides more useful information:
result = condition.holds()
assert result > 0, "Error with {0}".format(result)
3. Separation of concerns¶
This is a design principle that is applied at multiple levels. It is not just about the low-level design (code), but it is also relevant at a higher level of abstraction, so it will come up later when we talk about architecture.
Different responsibilities should go into different components, layers, or modules of the application. Each part of the program should only be responsible for a part of the functionality (what we call its concerns) and should know nothing about the rest.
The goal of separating concerns in software is to enhance maintainability by minimizing ripple effects. A ripple effect means the propagation of a change in the software from a starting point. This could be the case of an error or exception triggering a chain of other exceptions, causing failures that will result in a defect on a remote part of the application. It can also be that we have to change a lot of code scattered through multiple parts of the code base, as a result of a simple change in a function definition.
Clearly, we do not want these scenarios to happen. The software has to be easy to change. If we have to modify or refactor some part of the code that has to have a minimal impact on the rest of the application, the way to achieve this is through proper encapsulation.
In a similar way, we want any potential errors to be contained so that they don’t cause major damage.
This concept is related to the DbC principle in the sense that each concern can be enforced by a contract. When a contract is violated, and an exception is raised as a result of such a violation, we know what part of the program has the failure, and what responsibilities failed to be met.
Despite this similarity, separation of concerns goes further. We normally think of contracts between functions, methods, or classes, and while this also applies to responsibilities that have to be separated, the idea of separation of concerns also applies to Python modules, packages, and basically any software component.
3.1. Cohesion and coupling¶
These are important concepts for good software design.
On the one hand, cohesion means that objects should have a small and well-defined purpose, and they should do as little as possible. It follows a similar philosophy as Unix commands that do only one thing and do it well. The more cohesive our objects are, the more useful and reusable they become, making our design better.
On the other hand, coupling refers to the idea of how two or more objects depend on each other. This dependency poses a limitation. If two parts of the code (objects or methods) are too dependent on each other, they bring with them some undesired consequences:
No code reuse: If one function depends too much on a particular object, or takes too many parameters, it’s coupled with this object, which means that it will be really difficult to use that function in a different context (in order to do so, we will have to find a suitable parameter that complies with a very restrictive interface).
Ripple effects: Changes in one of the two parts will certainly impact the other, as they are too close
Low level of abstraction: When two functions are so closely related, it is hard to see them as different concerns resolving problems at different levels of abstraction
Note
Rule of thumb: Well-defined software will achieve high cohesion and low coupling.
4. Acronyms to live by¶
In this section, we will review some principles that yield some good design ideas. The point is to quickly relate to good software practices by acronyms that are easy to remember, working as a sort of mnemonic rule. If you keep these words in mind, you will be able to associate them with good practices more easily, and finding the right idea behind a particular line of code that you are looking at will be faster.
These are by no means formal or academic definitions, but more like empirical ideas that emerged from years of working in the software industry. Some of them do appear in books, as they were coined by important authors, and others have their roots probably in blog posts, papers, or conference talks.
4.1. DRY/OAOO¶
The ideas of Don’t Repeat Yourself (DRY) and Once and Only Once (OAOO) are closely related, so they were included together here. They are self-explanatory, you should avoid duplication at all costs.
Things in the code, knowledge, have to be defined only once and in a single place. When you have to make a change in the code, there should be only one rightful location to modify. Failure to do so is a sign of a poorly designed system.
Code duplication is a problem that directly impacts maintainability. It is very undesirable to have code duplication because of its many negative consequences:
It’s error prone: When some logic is repeated multiple times throughout the code, and this needs to change, it means we depend on efficiently correcting all the instances with this logic, without forgetting of any of them, because in that case there will be a bug.
It’s expensive: Linked to the previous point, making a change in multiple places takes much more time (development and testing effort) than if it was defined only once. This will slow the team down.
It’s unreliable: Also linked to the first point, when multiple places need to be changed for a single change in the context, you rely on the person who wrote the code to remember all the instances where the modification has to be made. There is no single source of truth.
Duplication is often caused by ignoring (or forgetting) that code represents knowledge. By giving meaning to certain parts of the code, we are identifying and labeling that knowledge.
Let’s see what this means with an example. Imagine that, in a study center, students are ranked by the following criteria: 11 points per exam passed, minus five points per exam failed, and minus two per year in the institution. The following is not actual code, but just a representation of how this might be scattered in a real code base:
def process_students_list(students):
# do some processing...
students_ranking = sorted(students, key=lambda s: s.passed * 11 - s.failed * 5 - s.years * 2)
# more processing
for student in students_ranking:
print(f"Name: {student.name}, Score: {student.passed * 11 - student.failed * 5 - student.years * 2}")
Notice how the lambda which is in the key of the sorted function represents some valid knowledge from the domain problem, yet it doesn’t reflect it (it doesn’t have a name, a proper and rightful location, there is no meaning assigned to that code, nothing). This lack of meaning in the code leads to the duplication we find when the score is printed out while listing the raking.
We should reflect our knowledge of our domain problem in our code, and our code will then be less likely to suffer from duplication and will be easier to understand:
def score_for_student(student):
return student.passed * 11 - student.failed * 5 - student.years * 2
def process_students_list(students):
# do some processing...
students_ranking = sorted(students, key=score_for_student)
# more processing
for student in students_ranking:
print(f"Name: {student.name}, Score: {core_for_student(student)}")
A fair disclaimer: this is just an analysis of one of the traits of code duplication. In reality, there are more cases, types, and taxonomies of code duplication, entire chapters could be dedicated to this topic, but here we focus on one particular aspect to make the idea behind the acronym clear.
In this example, we have taken what is probably the simplest approach to eliminating duplication: creating a function. Depending on the case, the best solution would be different. In some cases, there might be an entirely new object that has to be created (maybe an entire abstraction was missing). In other cases, we can eliminate duplication with a context manager. Iterators or generators could also help to avoid repetition in the code, and decorators will also help.
Unfortunately, there is no general rule or pattern to tell you which of the features of Python are the most suitable to address code duplication, but hopefully, after seeing the examples, and how the elements of Python are used, you will be able to develop your own intuition.
4.2. YAGNI¶
YAGNI (short for You Ain’t Gonna Need It) is an idea you might want to keep in mind very often when writing a solution if you do not want to over-engineer it.
We want to be able to easily modify our programs, so we want to make them future-proof. In line with that, many developers think that they have to anticipate all future requirements and create solutions that are very complex, and so create abstractions that are hard to read, maintain, and understand. Sometime later, it turns out that those anticipated requirements do not show up, or they do but in a different way (surprise!), and the original code that was supposed to handle precisely that does not work. The problem is that now it is even harder to refactor and extend our programs. What happened was that the original solution did not handle the original requirements correctly, and neither do the current ones, simply because it is the wrong abstraction.
Having maintainable software is not about anticipating future requirements. It is about writing software that only addresses current requirements in such a way that it will be possible (and easy) to change later on. In other words, when designing, make sure that your decisions don’t tie you down, and that you will be able to keep on building, but do not build more than what’s necessary.
4.3. KIS¶
KIS (stands for Keep It Simple) relates very much to the previous point. When you are designing a software component, avoid over-engineering it; ask yourself if your solution is the minimal one that fits the problem.
Implement minimal functionality that correctly solves the problem and does not complicate your solution more than is necessary. Remember: the simpler the design, the more maintainable it will be.
This design principle is an idea we will want to keep in mind at all levels of abstraction, whether we are thinking of a high-level design, or addressing a particular line of code.
At a high-level, think on the components we are creating. Do we really need all of them? Does this module a ctually require being utterly extensible right now? Emphasize the last part—maybe we want to make that component extensible, but now is not the right time, or it is not appropriate to do so because we still do not have enough information to create the proper abstractions, and trying to come up with generic interfaces at this point will only lead to even worse problems.
In terms of code, keeping it simple usually means using the smallest data structure that fits the problem. You will most likely find it in the standard library.
Sometimes, we might over-complicate code, creating more functions or methods than what’s necessary. The following class creates a namespace from a set of keyword arguments that have been provided, but it has a rather complicated code interface:
class ComplicatedNamespace:
"""An convoluted example of initializing an object with some
properties."""
ACCEPTED_VALUES = ("id_", "user", "location")
@classmethod
def init_with_data(cls, **data):
instance = cls()
for key, value in data.items():
if key in cls.ACCEPTED_VALUES:
setattr(instance, key, value)
return instance
Having an extra class method for initializing the object doesn’t seem really necessary. Then, the iteration, and the call to setattr inside it, make things even more strange, and the interface that is presented to the user is not very clear:
>>> cn = ComplicatedNamespace.init_with_data(
...
id_=42, user="root", location="127.0.0.1", extra="excluded"
... )
>>> cn.id_, cn.user, cn.location
(42, 'root', '127.0.0.1')
>>> hasattr(cn, "extra")
False
The user has to know of the existence of this other method, which is not convenient. It would be better to
keep it simple, and just initialize the object as we initialize any other object in Python (after all, there
is a method for that) with the __init__ method:
class Namespace:
"""Create an object from keyword arguments."""
ACCEPTED_VALUES = ("id_", "user", "location")
def __init__(self, **data):
accepted_data = {k: v for k, v in data.items() if k in self.ACCEPTED_VALUES}
self.__dict__.update(accepted_data)
Remember the zen of Python: simple is better than complex.
4.4. EAFP/LBYL¶
EAFP (stands for Easier to Ask Forgiveness than Permission), while LBYL (stands for Look Before You Leap).
The idea of EAFP is that we write our code so that it performs an action directly, and then we take care of the consequences later in case it doesn’t work. Typically, this means try running some code, expecting it to work, but catching an exception if it doesn’t, and then handling the corrective code on the except block.
This is the opposite of LBYL. As its name says, in the look before you leap approach, we first check what we are about to use. For example, we might want to check if a file is available before trying to operate with it:
if os.path.exists(filename):
with open(filename) as f:
...
This might be good for other programming languages, but it is not the Pythonic way of writing code. Python was built with ideas such as EAFP, and it encourages you to follow them (remember, explicit is better than implicit). This code would instead be rewritten like this:
try:
with open(filename) as f:
...
except FileNotFoundError as e:
logger.error(e)
Note
Prefer EAFP over LBYL.
5. Composition and inheritance¶
In object-oriented software design, there are often discussions as to how to address some problems by using the main ideas of the paradigm (polymorphism, inheritance, and encapsulation).
Probably the most commonly used of these ideas is inheritance: developers often start by creating a class hierarchy with the classes they are going to need and decide the methods each one should implement.
While inheritance is a powerful concept, it does come with its perils. The main one is that every time we extend a base class, we are creating a new one that is tightly coupled with the parent. As we have already discussed, coupling is one of the things we want to reduce to a minimum when designing software.
One of the main uses developers relate inheritance with is code reuse. While we should always embrace code reuse, it is not a good idea to force our design to use inheritance to reuse code just because we get the methods from the parent class for free. The proper way to reuse code is to have highly cohesive objects that can be easily composed and that could work on multiple contexts.
5.1. When inheritance is a good decision¶
We have to be careful when creating a derived class, because this is a double-edged sword—on the one hand, it has the advantage that we get all the code of the methods from the parent class for free, but on the other hand, we are carrying all of them to a new class, meaning that we might be placing too much functionality in a new definition.
When creating a new subclass, we have to think if it is actually going to use all of the methods it has just inherited, as a heuristic to see if the class is correctly defined. If instead, we find out that we do not need most of the methods, and have to override or replace them, this is a design mistake that could be caused by several reasons:
The superclass is vaguely defined and contains too much responsibility, instead of a well-defined interface.
The subclass is not a proper specialization of the superclass it is trying to extend.
A good case for using inheritance is the type of situation when you have a class that defines certain components with its behavior that are defined by the interface of this class (its public methods and attributes), and then you need to specialize this class in order to create objects that do the same but with something else added, or with some particular parts of its behavior changed.
You can find examples of good uses of inheritance in the Python standard library itself. For example, in the
http.server package, we can find a base class such as BaseHTTPRequestHandler, and subclasses such as
SimpleHTTPRequestHandler that extend this one by adding or changing part of its base interface.
Speaking of interface definition, this is another good use for inheritance. When we want to enforce the interface of some objects, we can create an abstract base class that does not implement the behavior itself, but instead just defines the interface—every class that extends this one will have to implement these to be a proper subtype.
Finally, another good case for inheritance is exceptions. We can see that the standard exception in Python
derives from Exception. This is what allows you to have a generic clause such as except Exception:,
which will catch every possible error. The important point is the conceptual one, they are classes derived
from Exception because they are more specific exceptions. This also works in well-known libraries such as
requests, for instance, in which an HTTPError is RequestException, which in turn is an IOError.
5.2. Anti-patterns for inheritance¶
If the previous section had to be summarized into a single word, it would be specialization. The correct use for inheritance is to specialize objects and create more detailed abstractions starting from base ones.
The parent (or base) class is part of the public definition of the new derived class. This is because the methods that are inherited will be part of the interface of this new class. For this reason, when we read the public methods of a class, they have to be consistent with what the parent class defines.
For example, if we see that a class derived from BaseHTTPRequestHandler implements a method named
handle(), it would make sense because it is overriding one of the parents. If it had any other method
whose name relates to an action that has to do with an HTTP request, then we could also think that is
correctly placed (but we would not think that if we found something called process_purchase() on that class).
The previous illustration might seem obvious, but it is something that happens very often, especially when developers try to use inheritance with the sole goal of reusing code. In the next example, we will see a typical situation that represents a common anti-pattern in Python: there is a domain problem that has to be represented, and a suitable data structure is devised for that problem, but instead of creating an object that uses such a data structure, the object becomes the data structure itself.
Let’s see these problems more concretely through an example. Imagine we have a system for managing insurance, with a module in charge of applying policies to different clients. We need to keep in memory a set of customers that are being processed at the time in order to apply those changes before further processing or persistence. The basic operations we need are to store a new customer with its records as satellite data, apply a change on a policy, or edit some of the data, just to name a few. We also need to support a batch operation, that is, when something on the policy itself changes (the one this module is currently processing), we have to apply these changes overall to customers on the current transaction.
Thinking in terms of the data structure we need, we realize that accessing the record for a particular
customer in constant time is a nice trait. Therefore, something like policy_transaction[customer_id]
looks like a nice interface. From this, we might think that a subscriptable object is a good idea, and further
on, we might get carried away into thinking that the object we need is a dictionary:
class TransactionalPolicy(collections.UserDict):
"""Example of an incorrect use of inheritance."""
def change_in_policy(self, customer_id, **new_policy_data):
self[customer_id].update(**new_policy_data)
With this code, we can get information about a policy for a customer by its identifier:
>>> policy = TransactionalPolicy({
...
"client001": {
...
"fee": 1000.0,
...
"expiration_date": datetime(2020, 1, 3),
...
}
... })
>>> policy["client001"]
{'fee': 1000.0, 'expiration_date': datetime.datetime(2020, 1, 3, 0, 0)}
>>> policy.change_in_policy("client001", expiration_date=datetime(2020, 1,
4))
>>> policy["client001"]
{'fee': 1000.0, 'expiration_date': datetime.datetime(2020, 1, 4, 0, 0)}
Sure, we achieved the interface we wanted in the first place, but at what cost? Now, this class has a lot of extra behavior from carrying out methods that weren’t necessary:
>>> dir(policy)
[ # all magic and special method have been omitted for brevity...
'change_in_policy', 'clear', 'copy', 'data', 'fromkeys', 'get', 'items',
'keys', 'pop', 'popitem', 'setdefault', 'update', 'values']
There are (at least) two major problems with this design. On the one hand, the hierarchy is wrong. Creating a
new class from a base one conceptually means that it’s a more specific version of the class it’s extending
(hence the name). How is it that a TransactionalPolicy is a dictionary? Does this make sense? Remember,
this is part of the public interface of the object, so users will see this class, their hierarchy, and will
notice such an odd specialization, as well as its public methods.
This leads us to the second problem—coupling. The interface of the transactional policy now includes all
methods from a dictionary. Does a transactional policy really need methods such as pop() or items()?
However, there they are. They are also public, so any user of this interface is entitled to call them, with
whatever undesired side-effect they may carry. More on this point: we don’t really gain much by extending a
dictionary. The only method it actually needs to update for all customers affected by a change in the current
policy (change_in_policy()) is not on the base class, so we will have to define it ourselves either way.
This is a problem of mixing implementation objects with domain objects. A dictionary is an implementation object, a data structure, suitable for certain kinds of operation, and with a trade-off like all data structures. A transactional policy should represent something in the domain problem, an entity that is part of the problem we are trying to solve.
Hierarchies like this one are incorrect, and just because we get a few magic methods from a base class (to make the object subscriptable by extending a dictionary) is not reason enough to create such an extension. Implementation classes should be extending solely when creating other, more specific, implementation classes. In other words, extend a dictionary if you want to create another (more specific, or slightly modified) dictionary. The same rule applies to classes of the domain problem.
The correct solution here is to use composition. TransactionalPolicy is not a dictionary: it uses a
dictionary. It should store a dictionary in a private attribute, and implement __getitem__() by proxying from
that dictionary and then only implementing the rest of the public method it requires:
class TransactionalPolicy:
"""Example refactored to use composition."""
def __init__(self, policy_data, **extra_data):
self._data = {**policy_data, **extra_data}
def change_in_policy(self, customer_id, **new_policy_data):
self._data[customer_id].update(**new_policy_data)
def __getitem__(self, customer_id):
return self._data[customer_id]
def __len__(self):
return len(self._data)
This way is not only conceptually correct, but also more extensible. If the underlying data structure (which, for now, is a dictionary) is changed in the future, callers of this object will not be affected, so long as the interface is maintained. This reduces coupling, minimizes ripple effects, allows for better refactoring (unit tests ought not to be changed), and makes the code more maintainable.
5.3. Multiple inheritance in Python¶
Python supports multiple inheritance. As inheritance, when improperly used, leads to design problems, you could also expect that multiple inheritance will also yield even bigger problems when it’s not correctly implemented.
Multiple inheritance is, therefore, a double-edged sword. It can also be very beneficial in some cases. Just to be clear, there is nothing wrong with multiple inheritance, the only problem it has is that when it’s not implemented correctly, it will multiply the problems.
Multiple inheritance is a perfectly valid solution when used correctly, and this opens up new patterns (such as the adapter pattern) and mixins.
One of the most powerful applications of multiple inheritance is perhaps that which enables the creation of mixins. Before exploring mixins, we need to understand how multiple inheritance works, and how methods are resolved in a complex hierarchy.
5.3.1. Method Resolution Order (MRO)¶
Some people don’t like multiple inheritance because of the constraints it has in other programming languages, for instance, the so-called diamond problem. When a class extends from two or more, and all of those classes also extend from other base classes, the bottom ones will have multiple ways to resolve the methods coming from the top-level classes. The question is, which of these implementations is used?
Consider the following diagram, which has a structure with multiple inheritance.
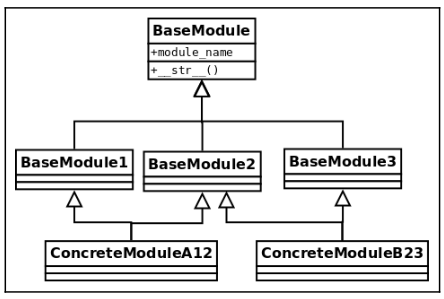
The top-level class has a class attribute and implements the __str__ method. Think of any of the concrete
classes, for example, ConcreteModuleA12: it extends from BaseModule1 and BaseModule2, and each one
of them will take the implementation of __str__ from BaseModule. Which of these two methods is going
to be the one for ConcreteModuleA12?
With the value of the class attribute, this will become evident:
class BaseModule:
module_name = "top"
def __init__(self, module_name):
self.name = module_name
def __str__(self):
return f"{self.module_name}:{self.name}"
class BaseModule1(BaseModule):
module_name = "module-1"
class BaseModule2(BaseModule):
module_name = "module-2"
class BaseModule3(BaseModule):
module_name = "module-3"
class ConcreteModuleA12(BaseModule1, BaseModule2):
"""Extend 1 & 2"""
class ConcreteModuleB23(BaseModule2, BaseModule3):
"""Extend 2 & 3"""
Now, let’s test this to see what method is being called:
>>> str(ConcreteModuleA12("test"))
'module-1:test'
There is no collision. Python resolves this by using an algorithm called C3 linearization or MRO, which defines a deterministic way in which methods are going to be called.
In fact, we can specifically ask the class for its resolution order:
>>> [cls.__name__ for cls in ConcreteModuleA12.mro()]
['ConcreteModuleA12', 'BaseModule1', 'BaseModule2', 'BaseModule', 'object']
Knowing about how the method is going to be resolved in a hierarchy can be used to our advantage when designing classes because we can make use of mixins.
5.3.2. Mixins¶
A mixin is a base class that encapsulates some common behavior with the goal of reusing code. Typically, a mixin class is not useful on its own, and extending this class alone will certainly not work, because most of the time it depends on methods and properties that are defined in other classes. The idea is to use mixin classes along with other ones, through multiple inheritance, so that the methods or properties used on the mixin will be available.
Imagine we have a simple parser that takes a string and provides iteration over it by its values separated by hyphens (-):
class BaseTokenizer:
def __init__(self, str_token):
self.str_token = str_token
def __iter__(self):
yield from self.str_token.split("-")
This is quite straightforward:
>>> tk = BaseTokenizer("28a2320b-fd3f-4627-9792-a2b38e3c46b0")
>>> list(tk)
['28a2320b', 'fd3f', '4627', '9792', 'a2b38e3c46b0']
But now we want the values to be sent in upper-case, without altering the base class. For this simple example,
we could just create a new class, but imagine that a lot of classes are already extending from
BaseTokenizer, and we don’t want to replace all of them. We can mix a new class into the hierarchy that
handles this transformation:
class UpperIterableMixin:
def __iter__(self):
return map(str.upper, super().__iter__())
class Tokenizer(UpperIterableMixin, BaseTokenizer):
pass
The new Tokenizer class is really simple. It doesn’t need any code because it takes advantage of the mixin.
This type of mixing acts as a sort of decorator. Based on what we just saw, Tokenizer will take __iter__
from the mixin, and this one, in turn, delegates to the next class on the line (by calling super()), which
is the BaseTokenizer, but it converts its values to uppercase, creating the desired effect.
6. Arguments in functions and methods¶
In Python, functions can be defined to receive arguments in several different ways, and these arguments can also be provided by callers in multiple ways.
There is also an industry-wide set of practices for defining interfaces in software engineering that closely relates to the definition of arguments in functions.
6.1. How function arguments work in Python¶
First, we will explore the particularities of how arguments are passed to functions in Python, and then we will review the general theory of good software engineering practices that relate to these concepts.
By first understanding the possibilities that Python offers for handling parameters, we will be able to assimilate general rules more easily, and the idea is that after having done so, we can easily draw conclusions on what good patterns or idioms are when handling arguments. Then, we can identify in which scenarios the Pythonic approach is the correct one, and in which cases we might be abusing the features of the language.
6.1.1. How arguments are copied to functions¶
The first rule in Python is that all arguments are passed by a value. Always. This means that when passing values to functions, they are assigned to the variables on the signature definition of the function to be later used on it. You will notice that a function changing arguments might depend on the type arguments: if we are passing mutable objects, and the body of the function modifies this, then, of course, we have side-effect that they will have been changed by the time the function returns.
In the following we can see the difference:
>>> def function(argument):
... argument += " in function"
... print(argument)
...
>>> immutable = "hello"
>>> function(immutable)
hello in function
>>> mutable = list("hello")
>>> immutable
'hello'
>>> function(mutable)
['h', 'e', 'l', 'l', 'o', ' ', 'i', 'n', ' ', 'f', 'u', 'n', 'c', 't', 'i', 'o', 'n']
>>> mutable
['h', 'e', 'l', 'l', 'o', ' ', 'i', 'n', ' ', 'f', 'u', 'n', 'c', 't', 'i', 'o', 'n']
This might look like an inconsistency, but it’s not. When we pass the first argument, a string, this is
assigned to the argument on the function. Since string objects are immutable, a statement like
argument += <expression> will in fact create the new object, argument + <expression>, and assign
that back to the argument. At that point, an argument is just a local variable inside the scope of the
function and has nothing to do with the original one in the caller.
On the other hand, when we pass list, which is a mutable object, then that statement has a different meaning
(it’s actually equivalent to calling .extend() on that list). This operator acts by modifying the list
in-place over a variable that holds a reference to the original list object, hence modifying it.
We have to be careful when dealing with these types of parameter because it can lead to unexpected side-effects. Unless you are absolutely sure that it is correct to manipulate mutable arguments in this way, we would recommend avoiding it and going for alternatives without these problems.
Note
Don’t mutate function arguments. In general, try to avoid side-effects in functions as much as possible.
Arguments in Python can be passed by position, as in many other programming languages, but also by keyword. This means that we can explicitly tell the function which values we want for which of its parameters. The only caveat is that after a parameter is passed by keyword, the rest that follow must also be passed this way, otherwise, SyntaxError will be raised.
6.1.2. Variable number of arguments¶
Python, as well as other languages, has built-in functions and constructions that can take a variable number of arguments. Consider for example string interpolation functions (whether it be by using the % operator or the format method for strings), which follow a similar structure to the printf function in C, a first positional parameter with the string format, followed by any number of arguments that will be placed on the markers of that formatting string.
Besides taking advantage of these functions that are available in Python, we can also create our own, which will work in a similar fashion. In this section, we will cover the basic principles of functions with a variable number of arguments, along with some recommendations, so that in the next section, we can explore how to use these features to our advantage when dealing with common problems, issues, and constraints that functions might have if they have too many arguments.
For a variable number of positional arguments, the star symbol (*) is used, preceding the name of the
variable that is packing those arguments. This works through the packing mechanism of Python.
Let’s say there is a function that takes three positional arguments. In one part of the code, we conveniently
happen to have the arguments we want to pass to the function inside a list, in the same order as they are
expected by the function. Instead of passing them one by one by the position (that is, list[0] to the
first element, list[1] to the second, and so on), which would be really un-Pythonic, we can use the
packing mechanism and pass them all together in a single instruction:
>>> def f(first, second, third):
... print(first)
... print(second)
... print(third)
...
>>> l = [1, 2, 3]
>>> f(*l)
1
2
3
The nice thing about the packing mechanism is that it also works the other way around. If we want to extract the values of a list to variables, by their respective position, we can assign them like this:
>>> a, b, c = [1, 2, 3]
>>> a
1
>>> b
2
>>> c
3
Partial unpacking is also possible. Let’s say we are just interested in the first values of a sequence (this can be a list, tuple, or something else), and after some point we just want the rest to be kept together. We can assign the variables we need and leave the rest under a packaged list. The order in which we unpack is not limited. If there is nothing to place in one of the unpacked subsections, the result will be an empty list:
>>> def show(e, rest):
... print("Element: {0} - Rest: {1}".format(e, rest))
...
>>> first, *rest = [1, 2, 3, 4, 5]
>>> show(first, rest)
Element: 1 - Rest: [2, 3, 4, 5]
>>> *rest, last = range(6)
>>> show(last, rest)
Element: 5 - Rest: [0, 1, 2, 3, 4]
>>> first, *middle, last = range(6)
>>> first
0
>>> middle
[1, 2, 3, 4]
>>> last
5
>>> first, last, *empty = (1, 2)
>>> first
1
>>> last
2
>>> empty
[]
One of the best uses for unpacking variables can be found in iteration. When we have to iterate over a sequence of elements, and each element is, in turn, a sequence, it is a good idea to unpack at the same time each element is being iterated over. To see an example of this in action, we are going to pretend that we have a function that receives a list of database rows, and that it is in charge of creating users out of that data. The first implementation takes the values to construct the user with from the position of each column in the row, which is not idiomatic at all. The second implementation uses unpacking while iterating:
USERS = [(i, f"first_name_{i}", "last_name_{i}") for i in range(1_000)]
class User:
def __init__(self, user_id, first_name, last_name):
self.user_id = user_id
self.first_name = first_name
self.last_name = last_name
def bad_users_from_rows(dbrows) -> list:
"""A bad case (non-pythonic) of creating ``User``s from DB rows."""
return [User(row[0], row[1], row[2]) for row in dbrows]
def users_from_rows(dbrows) -> list:
"""Create ``User``s from DB rows."""
return [User(user_id, first_name, last_name) for (user_id, first_name, last_name) in dbrows]
Notice that the second version is much easier to read. In the first version of the function
(bad_users_from_rows), we have data expressed in the form row[0], row[1], and row[2], which
doesn’t tell us anything about what they are. On the other hand, variables such as user_id, first_name,
and last_name speak for themselves.
We can leverage this kind of functionality to our advantage when designing our own functions.
An example of this that we can find in the standard library lies in the max function, which is defined as follows:
max(...)
max(iterable, *[, default=obj, key=func]) -> value
max(arg1, arg2, *args, *[, key=func]) -> value
With a single iterable argument, return its biggest item. The default keyword-only argument specifies an object to return if the provided iterable is empty.
With two or more arguments, return the largest argument.
There is a similar notation, with two stars ( ** ) for keyword arguments. If we have a dictionary and we pass it with a double star to a function, what it will do is pick the keys as the name for the parameter, and pass the value for that key as the value for that parameter in that function.
For instance, check this out:
function(**{"key": "value"})
It is the same as the following:
function(key="value")
Conversely, if we define a function with a parameter starting with two-star symbols, the opposite will happen: keyword-provided parameters will be packed into a dictionary:
>>> def function(**kwargs):
... print(kwargs)
...
>>> function(key="value")
{'key': 'value'}
6.2. The number of arguments in functions¶
Having functions or methods that take too many arguments is a sign of bad design (a code smell). Then, we propose ways of dealing with this issue.
The first alternative is a more general principle of software design: reification (creating a new object for all of those arguments that we are passing, which is probably the abstraction we are missing). Compacting multiple arguments into a new object is not a solution specific to Python, but rather something that we can apply in any programming language.
Another option would be to use the Python-specific features we saw in the previous section, making use of variable positional and keyword arguments to create functions that have a dynamic signature. While this might be a Pythonic way of proceeding, we have to be careful not to abuse the feature, because we might be creating something that is so dynamic that it is hard to maintain. In this case, we should take a look at the body of the function. Regardless of the signature, and whether the parameters seem to be correct, if the function is doing too many different things responding to the values of the parameters, then it is a sign that it has to be broken down into multiple smaller functions (remember, functions should do one thing, and one thing only!).
6.2.1. Function arguments and coupling¶
The more arguments a function signature has, the more likely this one is going to be tightly coupled with the caller function.
Let’s say we have two functions, f1, and f2, and the latter takes five parameters. The more parameters
f2 takes, the more difficult it would be for anyone trying to call that function to gather all that
information and pass it along so that it can work properly.
Now, f1 seems to have all of this information because it can call it correctly. From this, we can derive
two conclusions: first, f2 is probably a leaky abstraction, which means that since f1 knows everything
that f2 requires, it can pretty much figure out what it is doing internally and will be able to do it by
itself. So, all in all, f2 is not abstracting that much. Second, it looks like f2 is only useful to
f1, and it is hard to imagine using this function in a different context, making it harder to reuse.
When functions have a more general interface and are able to work with higher-level abstractions, they become more reusable.
This applies to all sort of functions and object methods, including the __init__ method for classes. The
presence of a method like this could generally (but not always) mean that a new higher-level abstraction
should be passed instead, or that there is a missing object.
Note
If a function needs too many parameters to work properly, consider it a code smell.
In fact, this is such a design problem that static analysis tools will, by default, raise a warning about when they encounter such a case. When this happens, don’t suppress the warning, refactor it instead.
6.2.2. Compact function signatures that take too many arguments¶
Suppose we find a function that requires too many parameters. We know that we cannot leave the code base like that, and a refactor is imperative. But, what are the options? Depending on the case, some of the following rules might apply. This is by no means extensive, but it does provide an idea of how to solve some scenarios that occur quite often.
Sometimes, there is an easy way to change parameters if we can see that most of them belong to a common object. For example, consider a function call like this one:
track_request(request.headers, request.ip_addr, request.request_id)
Now, the function might or might not take additional arguments, but something is really obvious here: all of
the parameters depend upon request, so why not pass the request object instead? This is a simple change,
but it significantly improves the code. The correct function call should be track_request(request): not to
mention that, semantically, it also makes much more sense.
While passing around parameters like this is encouraged, in all cases where we pass mutable objects to functions, we must be really careful about side-effects. The function we are calling should not make any modifications to the object we are passing because that will mutate the object, creating an undesired side-effect. Unless this is actually the desired effect (in which case, it must be made explicit), this kind of behavior is discouraged. Even when we actually want to change something on the object we are dealing with, a better alternative would be to copy it and return a (new) modified version of it.
Note
Work with immutable objects, and avoid side-effects as much as possible.
This brings us to a similar topic: grouping parameters. In the previous example, the parameters were already grouped, but the group (in this case, the request object) was not being used. But other cases are not as obvious as that one, and we might want to group all the data in the parameters in a single object that acts as a container. Needless to say, this grouping has to make sense. The idea here is to reify: create the abstraction that was missing from our design.
If the previous strategies don’t work, as a last resort we can change the signature of the function to accept
a variable number of arguments. If the number of arguments is too big, using *args or **kwargs will
make things harder to follow, so we have to make sure that the interface is properly documented and correctly
used, but in some cases this is worth doing.
It’s true that a function defined with *args and **kwargs is really flexible and adaptable, but the
disadvantage is that it loses its signature, and with that, part of its meaning, and almost all of its
legibility. We have seen examples of how names for variables (including function arguments) make the code much
easier to read. If a function will take any number of arguments (positional or keyword), we might find out
that when we want to take a look at that function in the future, we probably won’t know exactly what it was
supposed to do with its parameters, unless it has a very good docstring.
7. Final remarks on good practices for software design¶
A good software design involves a combination of following good practices of software engineering and taking advantage of most of the features of the language. There is a great value in using everything that Python has to offer, but there is also a great risk of abusing this and trying to fit complex features into simple designs.
In addition to this general principle, it would be good to add some final recommendations.
7.1. Orthogonality in software¶
This word is very general and can have multiple meanings or interpretations. In math, orthogonal means that two elements are independent. If two vectors are orthogonal, their scalar product is zero. It also means they are not related at all: a change in one of them doesn’t affect the other one at all. That’s the way we should think about our software.
Changing a module, class, or function should have no impact on the outside world to that component that is being modified. This is of course highly desirable, but not always possible. But even for cases where it’s not possible, a good design will try to minimize the impact as much as possible. We have seen ideas such as separation of concerns, cohesion, and isolation of components.
In terms of the runtime structure of software, orthogonality can be interpreted as the fact that makes changes (or side-effects) local. This means, for instance, that calling a method on an object should not alter the internal state of other (unrelated) objects. We have already (and will continue to do so) emphasized the importance of minimizing side-effects in our code.
In the example with the mixin class, we created a tokenizer object that returned an iterable. The fact that
the __iter__ method returned a new generator increases the chances that all three classes (the base,
the mixing, and the concrete class) are orthogonal. If this had returned something in concrete (a list, let’s
say), this would have created a dependency on the rest of the classes, because when we changed the list to
something else, we might have needed to update other parts of the code, revealing that the classes were not as
independent as they should be.
Let’s show you a quick example. Python allows passing functions by parameter because they are just regular objects. We can use this feature to achieve some orthogonality. We have a function that calculates a price, including taxes and discounts, but afterward we want to format the final price that’s obtained:
def calculate_price(base_price: float, tax: float, discount: float) ->
return (base_price * (1 + tax)) * (1 - discount)
def show_price(price: float) -> str:
return "$ {0:,.2f}".format(price)
def str_final_price(base_price: float, tax: float, discount: float, fmt_function=str) -> str:
return fmt_function(calculate_price(base_price, tax, discount))
Notice that the top-level function is composing two orthogonal functions. One thing to notice is how we
calculate the price, which is how the other one is going to be represented. Changing one does not change the
other. If we don’t pass anything in particular, it will use string conversion as the default representation
function, and if we choose to pass a custom function, the resulting string will change. However, changes in
show_price do not affect calculate_price . We can make changes to either function, knowing that the
other one will remain as it was:
>>> str_final_price(10, 0.2, 0.5)
'6.0'
>>> str_final_price(1000, 0.2, 0)
'1200.0'
>>> str_final_price(1000, 0.2, 0.1, fmt_function=show_price)
'$ 1,080.00'
There is an interesting quality aspect that relates to orthogonality. If two parts of the code are orthogonal, it means one can change without affecting the other. This implies that the part that changed has unit tests that are also orthogonal to the unit tests of the rest of the application. Under this assumption, if those tests pass, we can assume (up to a certain degree) that the application is correct without needing full regression testing.
More broadly, orthogonality can be thought of in terms of features. Two functionalities of the application can be totally independent so that they can be tested and released without having to worry that one might break the other (or the rest of the code, for that matter).
Imagine that the project requires a new authentication mechanism (oauth2, let’s say, but just for the sake
of the example), and at the same time another team is also working on a new report. Unless there is something
fundamentally wrong in that system, neither of those features should impact the other. Regardless of which one
of those gets merged first, the other one should not be affected at all.
7.2. Structuring the code¶
The way code is organized also impacts the performance of the team and its maintainability.
In particular, having large files with lots of definitions (classes, functions, constants, and so on) is a bad practice and should be discouraged. This doesn’t mean going to the extreme of placing one definition per file, but a good code base will structure and arrange components by similarity.
Luckily, most of the time, changing a large file into smaller ones is not a hard task in Python. Even if
multiple other parts of the code depend on definitions made on that file, this can be broken down into a
package, and will maintain total compatibility. The idea would be to create a new directory with a
__init__.py file on it (this will make it a Python package). Alongside this file, we will have multiple
files with all the particular definitions each one requires (fewer functions and classes grouped by a certain
criterion). Then, the __init__.py file will import from all the other files the definitions it previously
had (which is what guarantees its compatibility). Additionally, these definitions can be mentioned in the
__all__ variable of the module to make them exportable.
There are many advantages of this. Other than the fact that each file will be easier to navigate, and things will be easier to find, we could argue that it will be more efficient because of the following reasons:
It contains fewer objects to parse and load into memory when the module is imported
The module itself will probably be importing fewer modules because it needs fewer dependencies, like before
It also helps to have a convention for the project. For example, instead of placing constants in all of the
files, we can create a file specific to the constant values to be used in the project, and import it from
there: from myproject.constants import CONNECTION_TIMEOUT. Centralizing information like this makes it
easier to reuse code and helps to avoid inadvertent duplication.
More details about separating modules and creating Python packages will be discussed in Chapter 10, Clean Architecture, when we explore this in the context of software architecture.