Clean architecture¶
In this final chapter, we focus on how everything fits together in the design of a whole system. This is a more theoretical chapter. Given the nature of the topic, it would be too complex to delve down into the more low-level details. Besides, the point is precisely to escape from those details, assume that all the principles explored in previous chapters are assimilated, and focus on the design of a system at scale.
1. From clean code to clean architecture¶
This section is a discussion of how concepts that were emphasized in previous chapters reappear in a slightly different shape when we consider aspects of large systems. There is an interesting resemblance to how concepts that apply to more detailed design, as well as code, also apply to large systems and architectures.
The concepts explored in previously were related to single applications, generally, a project, that might be a single repository (or a few), for a source control version system (git). This is not to say that those design ideas are only applicable to code, or that they are of no use when thinking of an architecture, for two reasons: the code is the foundation of the architecture, and, if it’s not written carefully, the system will fail regardless of how well thought-out the architecture is.
Second, some principles that were revisited in previous chapters do not apply to code but are instead design ideas. The clearest example comes from design patterns. They are high- level ideas. With this, we can get a quick picture of how a component in our architecture might appear, without going into the details of the code.
But large enterprise systems typically consist of many of these applications, and now it’s time to start thinking in terms of a larger design, in the form of a distributed system.
In the following sections, we discuss the main topics that have been already discussed, but now from the perspective of a system.
1.1. Separation of concerns¶
Inside an application, there are multiple components. Their code is divided into other subcomponents, such as modules or packages, and the modules into classes or functions, and the classes into methods. The emphasis has been on keeping these components as small as possible, particularly in the case of functions, they should do one thing, and be small.
Several reasons were presented to justify this rationale. Small functions are easier to understand, follow, and debug. They are also easier to test. The smaller the pieces in our code, the easier it will be to write unit tests for it.
For the components of each application, we wanted different traits, mainly high cohesion, and low coupling. By dividing components into smaller units, each one with a single and well-defined responsibility, we achieve a better structure where changes are easier to manage. In the face of new requirements, there will be a single rightful place to make the changes, and the rest of the code should probably be unaffected.
When we talk about code, we say component to refer to one of these cohesive units (it might be a class, for example). When speaking in terms of an architecture, a component means anything in the system that can be treated as a working unit. The term component itself is quite vague, so there is no universally accepted definition in software architecture of what this means more concretely. The concept of a working unit is something that can vary from project to project. A component should be able to be released or deployed with its own cycles, independently from the rest of the parts of the system. And it is precisely that, one of the parts of a system, is namely the entire application.
For Python projects, a component could be a package, but a service can also be a component. Notice how two different concepts, with different levels of granularity, can be considered under the same category. To give an example, the event systems we used in previous chapters could be considered a component. It’s a working unit with a clearly defined purpose (to enrich events identified from logs), it can be deployed independently from the rest (whether as a Python package, or, if we expose its functionality, as a service), and it’s a part of the entire system, but not the whole application itself.
On the examples of previous chapters we have seen an idiomatic code, and we have also highlighted the importance of good design for our code, with objects that have single well- defined responsibilities, being isolated, orthogonal, and easier to maintain. This very same criteria, which applies to detailed design (functions, classes, methods), also applies to the components of a software architecture.
It’s probably undesirable for a large system to be just one component. A monolithic application will act as the single source of truth, responsible for everything in the system, and that will carry a lot of undesired consequences (harder to isolate and identify changes, to test effectively, and so on). In the same way, our code will be harder to maintain, if we are not careful and place everything in one place, the application will suffer from similar problems if its components aren’t treated with the same level of attention.
The idea of creating cohesive components in a system can have more than one implementation, depending on the level of abstraction we require.
One option would be to identify common logic that is likely to be reused multiple times and place it in a Python package (we will discuss the details later in the chapter). Another alternative would be to break the application into multiple smaller services, in a microservice architecture. The idea is to have components with a single and well-defined responsibility, and achieve the same functionality as a monolithic application by making those services cooperate, and exchange information.
1.2. Abstractions¶
This is where encapsulation appears again. From our systems (as we do in relation to the code), we want to speak in terms of the domain problem, and leave the implementation details as hidden as possible.
In the same way that the code has to be expressive (almost to the point of being self- documenting), and have the right abstractions that reveal the solution to the essential problem (minimizing accidental complexity), the architecture should tell us what the system is about. Details such as the solution used to persist data on disk, the web framework of choice, the libraries used to connect to external agents, and interaction between systems, are not relevant. What is relevant is what the system does. A concept such as a scream architecture (SCREAM) reflects this idea.
The dependency inversion principle (DIP) is of great help in this regard; we don’t want to depend upon concrete implementations but rather abstractions. In the code, we place abstractions (or interfaces) on the boundaries, the dependencies, those parts of the application that we don’t control and might change in the future. We do this because we want to invert the dependencies. Let them have to adapt to our code (by having to comply with an interface), and not the other way round.
Creating abstractions and inverting dependencies are good practices, but they’re not enough. We want our entire application to be independent and isolated from things that are out of our control. And this is even more than just abstracting with objects—we need layers of abstraction.
This is a subtle, but important difference with respect to the detailed design. In the DIP, it was recommended to create an interface, that could be implemented with the abc module from the standard library, for instance. Because Python works with duck typing, while using an abstract class might be helpful, it’s not mandatory, as we can easily achieve the same effect with regular objects as long as they comply with the required interface. The dynamic typing nature of Python allowed us to have these alternatives. When thinking in terms of architecture, there is no such a thing. As it will become clearer with the example, we need to abstract dependencies entirely, and there is no feature of Python that can do that for us.
Some might argue “Well, the ORM is a good abstraction for a database, isn’t it?” It’s not enough. The ORM itself is a dependency and, as such, out of our control. It would be even better to create an intermediate layer, an adapter, between the API of the ORM and our application.
This means that we don’t abstract the database just with an ORM; we use the abstraction layer we create on top of it, to define objects of our own that belong to our domain. The application then imports this component, and uses the entities provided by this layer, but not the other way round. The abstraction layer should not know about the logic of our application; it’s even truer that the database should know nothing about the application itself. If that were the case, the database would be coupled to our application. The goal is to invert the dependency—this layer provides an API, and every storage component that wants to connect has to conform to this API. This is the concept of a hexagonal architecture (HEX).
2. Software components¶
We have a large system now, and we need to scale it. It also has to be maintainable. At this point, the concerns aren’t only technical but also organizational. This means it’s not just about managing software repositories; each repository will most likely belong to an application, and it will be maintained by a team who owns that part of the system.
This demands we keep in mind how a large system is divided into different components. This can have many phases, from a very simple approach about, say, creating Python packages, to more complex scenarios in a microservice architecture.
The situation could be even more complex when different languages are involved, but in this chapter, we will assume they are all Python projects.
These components need to interact, as do the teams. The only way this can work at scale is if all the parts agree on an interface, a contract.
2.1. Packages¶
A Python package is a convenient way to distribute software and reuse code in a more general way. Packages that have been built can be published to an artifact repository (such as an internal PyPi server for the company), from where it will be downloaded by the rest of the applications that require it.
The motivation behind this approach has many elements to it: it’s about reusing code at large, and also achieving conceptual integrity.
Here, we discuss the basics of packaging a Python project that can be published in a repository. The default repository might be PyPi, but also internal; or custom setups will work with the same basics.
We are going to simulate that we have created a small library, and we will use that as an example to review the main points to take into consideration.
Aside from all the open source libraries available, sometimes we might need some extra functionality: perhaps our application uses a particular idiom repeatedly or relies on a function or mechanism quite heavily and the team has devised a better function for these particular needs. In order to work more effectively, we can place this abstraction into a library, and encourage all team members to use the idioms as provided by it, because doing so will help avoid mistakes and reduce bugs.
Potentially, there are infinite examples that could suit this scenario. Maybe the application needs to extract a lot of .tag.gz files (in a particular format) and has faced security problems in the past with malicious files that ended up with path traversal attacks. As a mitigation measure, the functionality for abstracting custom file formats securely was put in a library that wraps the default one and adds some extra checks. This sounds like a good idea.
Or maybe there is a configuration file that has to be written, or parsed in a particular format, and this requires many steps to be followed in order; again, creating a helper function to wrap this, and using it in all the projects that need it, constitutes a good investment, not only because it saves a lot of code repetition, but also because it makes it harder to make mistakes.
The gain is not only complying with the DRY principle (avoiding code duplication, encouraging reuse) but also that the abstracted functionality represents a single point of reference of how things should be done, hence contributing to the attainment of conceptual integrity.
In general, the minimum layout for a library would look like this:
.
├── Makefile
├── README.rst
├── setup.py
├── src
│ ├── apptool
│ ├── common.py
│ ├── __init__.py
│ └── parse.py
└── tests
├── integration
└── unit
The important part is the setup.py file, which contains the definition for the package. In
this file, all the important definitions of the project (its requirements, dependencies, name,
description, and so on) are specified.
The apptool directory under src is the name of the library we’re working on. This is a
typical Python project, so we place here all the files we need.
An example of the setup.py file could be:
from setuptools import find_packages, setup
with open("README.rst", "r") as longdesc:
long_description = longdesc.read()
setup(
name="apptool",
description="Description of the intention of the package",
long_description=long_description,
author="Dev team",
version="0.1.0",
packages=find_packages(where="src/"),
package_dir={"": "src"},
)
This minimal example contains the key elements of the project. The name argument in the
setup function is used to give the name that the package will have in the repository (under
this name, we run the command to install it, in this case its pip install apptool). It’s
not strictly required that it matches the name of the project directory (src/apptool), but
it’s highly recommended, so its easier for users.
The version is important to keep different releases going on, and then the packages are
specified. By using the find_packages() function, we automatically discover everything
that’s a package, in this case under the src/ directory. Searching under this directory helps
to avoid mixing up files beyond the scope of the project and, for instance, accidentally
releasing tests or a broken structure of the project.
A package is built by running the following commands, assuming its run inside a virtual environment with the dependencies installed:
$VIRTUAL_ENV/bin/pip install -U setuptools wheel
$VIRTUAL_ENV/bin/python setup.py sdist bdist_wheel
This will place the artifacts in the dist/ directory, from where they can be later published
either to PyPi or to the internal package repository of the company.
The key points in packaging a Python project are:
Test and verify that the installation is platform-independent and that it doesn’t rely on any local setup (this can be achieved by placing the source files under an
src/directory)Make sure that unit tests aren’t shipped as part of the package being built
Separate dependencies: what the project strictly needs to run is not the same as what developers require
It’s a good idea to create entry points for the commands that are going to be required the most
The setup.py file supports multiple other parameters and configurations and can be
effected in a much more complicated manner. If our package requires several operating
system libraries to be installed, it’s a good idea to write some logic in the setup.py file to
compile and build the extensions that are required. This way, if something is amiss, it will
fail early on in the installation process, and if the package provides a helpful error message,
the user will be able to fix the dependencies more quickly and continue.
Installing such dependencies represents another difficult step in making the application ubiquitous, and easy to run by any developer regardless of their platform of choice. The best way to surmount this obstacle is to abstract the platform by creating a Docker image.
2.2. Containers¶
This chapter is dedicated to architecture, so the term container refers to something
completely different from a Python container (an object with a __contains__ method).
A container is a process that runs in the operating
system under a group with certain restrictions and isolation considerations. Concretely we
refer to Docker containers, which allow managing applications (services or processes) as
independent components.
Containers represent another way of delivering software. Creating Python packages taking into account the considerations in the previous section is more suitable for libraries, or frameworks, where the goal is to reuse code and take advantage of using a single place where specific logic is gathered.
In the case of containers, the objective will not be creating libraries but applications (most of the time). However, an application or platform does not necessarily mean an entire service. The idea of building containers is to create small components that represent a service with a small and clear purpose.
In this section, we will mention Docker when we talk about containers, and we will explore the basics of how to create Docker images and containers for Python projects. Keep in mind that this is not the only technology for launching applications into containers, and also that it’s completely independent of Python.
A Docker container needs an image to run on, and this image is created from other base images. But the images we create can themselves serve as base images for other containers. We will want to do that in cases where there is a common base in our application that can be shared across many containers. A potential use would be creating a base image that installs a package (or many) in the way we described in the previous section, and also all of its dependencies, including those at the operating system level. A package we create can depend not only on other Python libraries, but also on a particular platform (a specific operating system), and particular libraries preinstalled in that operating system, without which the package will simply not install and will fail.
Containers are a great portability tool for this. They can help us ensure that our application will have a canonical way of running, and it will also ease the development process a lot (reproducing scenarios across environments, replicating tests, on-boarding new team members, and so on).
As packages are the way we reuse code and unify criteria, containers represent the way we create the different services of the application. They meet the criteria behind the principle of separation of concerns (SoC) of the architecture. Each service is another kind of component that will encapsulate a set of functionalities independently of the rest of the application. These containers ought to be designed in such a way that they favor maintainability: if the responsibilities are clearly divided, a change in a service should not impact any other part of the application whatsoever.
3. Use case¶
As an example of how we might organize the components of our application, and how the previous concepts might work in practice, we present the following simple example.
The use case is that there is an application for delivering food, and this application has a specific service for tracking the status of each delivery at its different stages. We are going to focus only on this particular service, regardless of how the rest of the application might appear. The service has to be really simple: a REST API that, when asked about the status of a particular order, will return a JSON response with a descriptive message.
We are going to assume that the information about each particular order is stored in a database, but this detail should not matter at all.
Our service has two main concerns for now: getting the information about a particular order (from wherever this might be stored), and presenting this information in a useful way to the clients (in this case, delivering the results in JSON format, exposed as a web service).
As the application has to be maintainable and extensible, we want to keep these two concerns as hidden as possible and focus on the main logic. Therefore, these two details are abstracted and encapsulated into Python packages that the main application with the core logic will use, as shown in the following diagram:
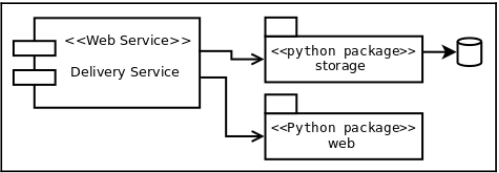
3.1. The code¶
The idea of creating Python packages in this example is to illustrate how abstracted and isolated components can be made, in order to work effectively. In reality, there is no actual need for these to be Python packages; we could just create the right abstractions as part of the “delivery service” project, and, while the correct isolation is preserved, it will work without any issues.
Creating packages makes more sense when there is logic that is going to be repeated and is expected to be used across many other applications (that will import from those packages) because we want to favor code reuse. In this particular case, there are no such requirements, so it might be beyond the scope of the design, but such distinction still makes more clear the idea of a “pluggable architecture” or component, something that is really a wrapper abstracting technical details we don’t really want to deal with, much less depend upon.
The storage package is in charge of retrieving the data that is required, and presenting
this to the next layer (the delivery service) in a convenient format, something that is suitable
for the business rules. The main application should now know where this data came from,
what its format is, and so on. This is the entire reason why we have such an abstraction in
between so the application doesn’t use a row or an ORM entity directly, but rather
something workable.
3.1.1. Domain models¶
The following definitions apply to classes for business rules. Notice that they are meant to be pure business objects, not bound to anything in particular. They aren’t models of an ORM, or objects of an external framework, and so on. The application should work with these objects (or objects with the same criteria).
In each case, the dosctring documents the purpose of each class, according to the business rule:
from typing import Union
class DispatchedOrder:
"""An order that was just created and notified to start its delivery."""
status = "dispatched"
def __init__(self, when):
self._when = when
def message(self) -> dict:
return {
"status": self.status,
"msg": f"Order was dispatched on {self._when.isoformat()}"
}
class OrderInTransit:
"""An order that is currently being sent to the customer."""
status = "in transit"
def __init__(self, current_location):
self._current_location = current_location
def message(self) -> dict:
return {
"status": self.status,
"msg": f"The order is in progress (current location: {self._current_location})"
}
class OrderDelivered:
"""An order that was already delivered to the customer."""
status = "delivered"
def __init__(self, delivered_at):
self._delivered_at = delivered_at
def message(self) -> dict:
return {
"status": self.status,
"msg": f"Order delivered on {self._delivered_at.isoformat()}"
}
class DeliveryOrder:
def __init__(self, delivery_id: str, status: Union[DispatchedOrder, OrderInTransit, OrderDelivered]) -> None:
self._delivery_id = delivery_id
self._status = status
def message(self) -> dict:
return {"id": self._delivery_id, **self._status.message()}
From this code, we can already get an idea of what the application will look like: we want
to have a DeliveryOrder object, which will have its own status (as an internal
collaborator), and once we have that, we will call its message() method to return this
information to the user.
3.1.2. Calling from the application¶
Here is how these objects are going to be used in the application. Notice how this depends on the previous packages ( web and storage ), but not the other way round:
from storage import DBClient, DeliveryStatusQuery, OrderNotFoundError
from web import NotFound, View, app, register_route
class DeliveryView(View):
async def _get(self, request, delivery_id: int):
dsq = DeliveryStatusQuery(int(delivery_id), await DBClient())
try:
result = await dsq.get()
except OrderNotFoundError as e:
raise NotFound(str(e)) from e
return result.message()
register_route(DeliveryView, "/status/<delivery_id:int>")
In the previous section, the domain objects were shown and here the code for the application is displayed. Aren’t we missing something? Sure, but is it something we really need to know now? Not necessarily.
The code inside the storage and web packages was deliberately left out. Also, and this was done on purpose, the names of
such packages were chosen so as not to reveal any technical detail: storage and web.
Look again at the code in the previous listing. Can you tell which frameworks are being used? Does it say whether the data comes from a text file, a database (if so, of what type? SQL? NoSQL?), or another service (the web, for instance)? Assume that it comes from a relational database. Is there any clue to how this information is retrieved? Manual SQL queries? Through an ORM? What about the web? Can we guess what frameworks are used?
The fact that we cannot answer any of those questions is probably a good sign. Those are details, and details ought to be encapsulated. We can’t answer those questions unless we take a look at what’s inside those packages.
There is another way of answering the previous questions, and it comes in the form of a
question itself: why do we need to know that? Looking at the code, we can see that there is
a DeliveryOrder, created with an identifier of a delivery, and that it has a get() method,
which returns an object representing the status of the delivery. If all of this information is
correct, that’s all we should care about. What difference does it make how is it done?
The abstractions we created make our code declarative. In declarative programming, we declare the problem we want to solve, not how we want to solve it. It’s the opposite of imperative, in which we have to make all the steps required explicit in order to get something (for instance connect to the database, run this query, parse the result, load it into this object, and so on). In this case, we are declaring that we just want to know the status of the delivery given by some identifier.
These packages are in charge of dealing with the details and presenting what the
application needs in a convenient format, namely objects of the kind presented in the
previous section. We just have to know that the storage package contains an object that,
given an ID for a delivery and a storage client (this dependency is being injected into this
example for simplicity, but other alternatives are also possible), it will
retrieve DeliveryOrder which we can then ask to compose the message.
This architecture provides convenience and makes it easier to adapt to changes, as it protects the kernel of the business logic from the external factors that can change.
Imagine we want to change how the information is retrieved. How hard would that be? The application relies on an API, like the following one:
dsq = DeliveryStatusQuery(int(delivery_id), await DBClient())
So it would be about just changing how the get() method works, adapting it to the new
implementation detail. All we need is for this new object to return DeliveryOrder on
its get() method and that would be all. We can change the query, the ORM, the database,
and so on, and, in all cases, the code in the application does not need to change!
3.1.3. Adapters¶
Still, without looking at the code in the packages, we can conclude that they work as interfaces for the technical details of the application.
In fact, since we are seeing the application from a high-level perspective, without needing to look at the code, we can imagine that inside those packages there must be an implementation of the adapter design pattern. One or more of these objects is adapting an external implementation to the API defined by the application. This way, dependencies that want to work with the application must conform to the API, and an adapter will have to be made.
Notice how the view is constructed. It inherits from a class named View that comes from our web
package. We can deduce that this View is, in turn, a class derived from one of the web
frameworks that might be being used, creating an adapter by inheritance. The important
thing to note is that once this is done, the only object that matters is our View class, because,
in a way, we are creating our own framework, which is based on adapting an existing one
(but again changing the framework will mean just changing the adapters, not the entire
application).
3.2. The services¶
To create the service, we are going to launch the Python application inside a Docker container. Starting from a base image, the container will have to install the dependencies for the application to run, which also has dependencies at the operating system level.
This is actually a choice because it depends on how the dependencies are used. If a package we use requires other libraries on the operating system to compile at installation time, we can avoid this simply by building a wheel for our platform of the library and installing this directly. If the libraries are needed at runtime, then there is no choice but to make them part of the image of the container.
Now, we discuss one of the many ways of preparing a Python application to be run inside a Docker container. This is one of numerous alternatives for packaging a Python project into a container. First, we take a look at what the structure of the directories looks like:
.
├── Dockerfile
├── libs
│ ├── README.rst
│ ├── storage
│ └── web
├── Makefile
├── README.rst
├── setup.py
└── statusweb
├── __init__.py
└── service.py
The libs directory can be ignored since it’s just the place where the dependencies are
placed (it’s displayed here to keep them in mind when they are referenced in the setup.py
file, but they could be placed in a different repository and installed remotely via pip).
We have Makefile with some helper commands, then the setup.py file, and the
application itself inside the statusweb directory. A common difference between packaging
applications and libraries is that while the latter specify their dependencies in
the setup.py file, the former has a requirements.txt file from where dependencies are
installed via pip install -r requirements.txt. Normally, we would do this in the
Dockerfile, but in order to keep things simpler in this particular example, we will assume
that taking the dependencies from the setup.py file is enough. This is because, besides this
consideration, there are a lot more considerations to be taken into account when dealing
with dependencies, such as freezing the version of the packages, tracking indirect
dependencies, using extra tools such as pipenv, and more topics that are beyond the scope
of the chapter. In addition, it is also customary to make the setup.py file read
from requirements.txt for consistency.
Now we have the content of the setup.py file, which states some details of the application:
from setuptools import find_packages, setup
with open("README.rst", "r") as longdesc:
long_description = longdesc.read()
install_requires = ["web", "storage"]
setup(
name="delistatus",
description="Check the status of a delivery order",
long_description=long_description,
author="Dev team",
version="0.1.0",
packages=find_packages(),
install_requires=install_requires,
entry_points={
"console_scripts": [
"status-service = statusweb.service:main",
],
}
)
The first thing we notice is that the application declares its dependencies, which are the
packages we created and placed under libs/, namely web and storage, abstracting and
adapting to some external components. These packages, in turn, will have dependencies, so
we will have to make sure the container installs all the required libraries when the image is
being created so that they can install successfully, and then this package afterward.
The second thing we notice is the definition of the entry_points keyword argument
passed to the setup function. This is not strictly mandatory, but it’s a good idea to create an
entry point. When the package is installed in a virtual environment, it shares this directory
along with all its dependencies. A virtual environment is a structure of directories with the
dependencies of a given project. It has many subdirectories, but the most important ones
are:
<virtual-env-root>/lib/<python-version>/site-packages
<virtual-env-root>/bin
The first one contains all the libraries installed in that virtual environment. If we were to
create a virtual environment with this project, that directory would contain the web,
and storage packages, along with all its dependencies, plus some extra basic ones and the
current project itself.
The second, /bin/, contains the binary files and commands available when that virtual
environment is active. By default, it would just be the version of Python, pip, and some
other basic commands. When we create an entry point, a binary with that declared name is
placed there, and, as a result, we have that command available to run when the
environment is active. When this command is called, it will run the function that is
specified with all the context of the virtual environment. That means it is a binary we can
call directly without having to worry about whether the virtual environment is active, or
whether the dependencies are installed in the path that is currently running.
The definition is the following one: "status-service = statusweb.service:main"
The left-hand side of the equals sign declares the name of the entry point. In this case, we
will have a command named status-service available. The right-hand side declares how
that command should be run. It requires the package where the function is defined,
followed by the function name after :. In this case, it will run the main function declared in
statusweb/service.py.
This is followed by a definition of the Dockerfile:
FROM python:3.6.6-alpine3.6
RUN apk add --update \
python-dev \
gcc \
musl-dev \
make
WORKDIR /app
ADD . /app
RUN pip install /app/libs/web /app/libs/storage
RUN pip install /app
EXPOSE 8080
CMD ["/usr/local/bin/status-service"]
The image is built based on a lightweight Python image, and then the operating system
dependencies are installed so that our libraries can be installed. Following the previous
consideration, this Dockerfile simply copies the libraries, but this might as well be
installed from a requirements.txt file accordingly. After all the pip install
commands are ready, it copies the application in the working directory, and the entry point
from Docker (the CMD command, not to be confused with the Python one) calls the entry
point of the package where we placed the function that launches the process.
All the configuration is passed by environment variables, so the code for our service will have to comply with this norm.
In a more complex scenario involving more services and dependencies, we will not just run
the image of the created container, but instead declare a docker-compose.yml file with
the definitions of all the services, base images, and how they are linked and interconnected.
Now that we have the container running, we can launch it and run a small test on it to get an idea of how it works:
$ curl http://localhost:8080/status/1
{"id":1,"status":"dispatched","msg":"Order was dispatched on
2018-08-01T22:25:12+00:00"}
3.3. Analysis¶
There are many conclusions to be drawn from the previous implementation. While it might seem like a good approach, there are cons that come with the benefits; after all, no architecture or implementation is perfect. This means that a solution such as this one cannot be good for all cases, so it will pretty much depend on the circumstances of the project, the team, the organization, and more.
While it’s true that the main idea of the solution is to abstract details as much as possible, as we shall see some parts cannot be fully abstracted away, and also the contracts between the layers imply an abstraction leak.
3.3.1. The dependency flow¶
Notice that dependencies flow in only one direction, as they move closer to the kernel,
where the business rules lie. This can be traced by looking at the import statements. The
application imports everything it needs from storage, for example, and in no part is this
inverted.
Breaking this rule would create coupling. The way the code is arranged now means that
there is a weak dependency between the application and storage. The API is such that we
need an object with a get() method, and any storage that wants to connect to the
application needs to implement this object according to this specification. The dependencies
are therefore inverted: it’s up to every storage to implement this interface, in order to
create an object according to what the application is expecting.
3.3.2. Limitations¶
Not everything can be abstracted away. In some cases, it’s simply not possible, and in others, it might not be convenient. Let’s start with the convenience aspect.
In this example, there is an adapter of the web framework of choice to a clean API to be presented to the application. In a more complex scenario, such a change might not be possible. Even with this abstraction, parts of the library were still visible to the application. Adapting an entire framework might not only be hard but also not possible in some cases. It’s not entirely a problem to be completely isolated from the web framework because, sooner or later, we will need some of its features or technical details.
The important takeaway here is not the adapter, but the idea of hiding technical details as
much as possible. That means, that the best thing that was displayed on the listing for the
code of the application was not the fact that there was an adapter between our version of
the web framework and the actual one, but instead the fact that the latter was not
mentioned by name in any part of the visible code. The service was made clear that web
was just a dependency (a detail being imported), and revealed the intention behind what it
was supposed to do. The goal is to reveal the intention (as in the code) and to defer details
as much as possible.
As to what things cannot be isolated, those are the elements that are closest to the code. In this case, the web application was using the objects operating within them in an asynchronous fashion. That is a hard constraint we cannot circumvent. It’s true that whatever is inside the storage package can be changed, refactored, and modified, but whatever these modifications might be, it still needs to preserve the interface, and that includes the asynchronous interface.
3.3.3. Testability¶
Again, much like with the code, the architecture can benefit from separating pieces into smaller components. The fact that dependencies are now isolated and controlled by separate components leaves us with a cleaner design for the main application, and now it’s easier to ignore the boundaries to focus on testing the core of the application.
We could create a patch for the dependencies, and write unit tests that are simpler (they won’t need a database), or to launch an entire web service, for instance. Working with pure domain objects means it will be easier to understand the code and the unit tests. Even the adapters will not need that much testing because their logic should be very simple.
3.3.4. Intention revealing¶
These details included keeping functions short, concerns separated, dependencies isolated, and assigning the right meaning to abstractions in every part of the code. Intention revealing was a critical concept for our code: every name has to be wisely chosen, clearly communicating what it’s supposed to do. Every function should tell a story.
A good architecture should reveal the intent of the system it entails. It should not mention the tools it’s built with; those are details, and as we discussed at length, details should be hidden, encapsulated.